论文阅读:SSD: Single Shot MultiBox Detector
Preface
这是今年 ECCV 2016 的1篇文章,是 UNC Chapel Hill(北卡罗来纳大学教堂山分校) 的 Wei Liu 大神的新作,论文代码:https://github.com/weiliu89/caffe/tree/ssd

有几点更新:
1. 看到1篇 blog 对检测做了1个总结、搜集,强烈推荐: Object Detection
2. 还有,今天在微博上看到 VOC2012 的榜单又被刷新了,微博原地址为:这里,以下图:

3. 目前 voc 2012 的榜单 以下:

做目标检测这块的多关注哦~
Abstract
这篇文章在既保证速度,又要保证精度的情况下,提出了 SSD 物体检测模型,与现在流行的检测模型1样,将检测进程全部成1个 single deep neural network。便于训练与优化,同时提高检测速度。
SSD 将输出1系列 离散化(discretization) 的 bounding boxes,这些 bounding boxes 是在 不同层次(layers) 上的 feature maps 上生成的,并且有着不同的 aspect ratio。
在 prediction 阶段:
-
要计算出每个 default box 中的物体,其属于每一个种别的可能性,即 score,得分。如对 PASCAL VOC 数据集,总共有 20 类,那末得出每个 bounding box 中物体属于这 20 个种别的每种的可能性。
-
同时,要对这些 bounding boxes 的 shape 进行微调,以使得其符合物体的 外接矩形。
-
还有就是,为了处理相同物体的不同尺寸的情况,SSD 结合了不同分辨率的 feature maps 的 predictions。
相对那些需要 object proposals 的检测模型,本文的 SSD 方法完全取消了 proposals generation、pixel resampling 或 feature resampling 这些阶段。这样使得 SSD 更容易去优化训练,也更容易地将检测模型融会进系统当中。
在 PASCAL VOC、MS COCO、ILSVRC 数据集上的实验显示,SSD 在保证精度的同时,其速度要比用 region proposals 的方法要快很多。
SSD 相比较于其他单结构模型(YOLO),SSD 获得更高的精度,即是是在输入图象较小的情况下。如输入 300×300 大小的 PASCAL VOC 2007 test 图象,在 Titan X 上,SSD 以 58 帧的速率,同时获得了 72.1% 的 mAP。
如果输入的图象是 500×500,SSD 则获得了 75.1% 的 mAP,比目前最 state-of-art 的 Faster R-CNN 要好很多。
Introduction
现金流行的 state-of-art 的检测系统大致都是以下步骤,先生成1些假定的 bounding boxes,然后在这些 bounding boxes 中提取特点,以后再经过1个分类器,来判断里面是否是物体,是甚么物体。
这类 pipeline 自从 IJCV 2013, Selective Search for Object Recognition 开始,到如今在 PASCAL VOC、MS COCO、ILSVRC 数据集上获得领先的基于 Faster R-CNN 的 ResNet 。但这类方法对嵌入式系统,所需要的计算时间太久了,不足以实时的进行检测。固然也有很多工作是朝着实时检测迈进,但目前为止,都是牺牲检测精度来换取时间。
本文提出的实时检测方法,消除中间的 bounding boxes、pixel or feature resampling 的进程。虽然本文不是第1篇这样做的文章(YOLO),但是本文做了1些提升性的工作,既保证了速度,也保证了检测精度。
这里面有1句非常关键的话,基本概括了本文的核心思想:
Our improvements include using a small convolutional filter to predict object categories and offsets in bounding box locations, using separate predictors (filters) for different aspect ratio detections, and applying these filters to multiple feature maps from the later stages of a network in order to perform detection at multiple scales.
本文的主要贡献总结以下:
-
提出了新的物体检测方法:SSD,比本来最快的 YOLO: You Only Look Once 方法,还要快,还要精确。保证速度的同时,其结果的 mAP 可与使用 region proposals 技术的方法(如 Faster R-CNN)相媲美。
-
SSD 方法的核心就是 predict object(物体),和其 归属种别的 score(得分);同时,在 feature map 上使用小的卷积核,去 predict 1系列 bounding boxes 的 box offsets。
-
本文中为了得到高精度的检测结果,在不同层次的 feature maps 上去 predict object、box offsets,同时,还得到不同 aspect ratio 的 predictions。
-
本文的这些改进设计,能够在当输入分辨率较低的图象时,保证检测的精度。同时,这个整体 end-to-end 的设计,训练也变得简单。在检测速度、检测精度之间获得较好的 trade-off。
-
本文提出的模型(model)在不同的数据集上,如 PASCAL VOC、MS COCO、ILSVRC, 都进行了测试。在检测时间(timing)、检测精度(accuracy)上,均与目前物体检测领域 state-of-art 的检测方法进行了比较。
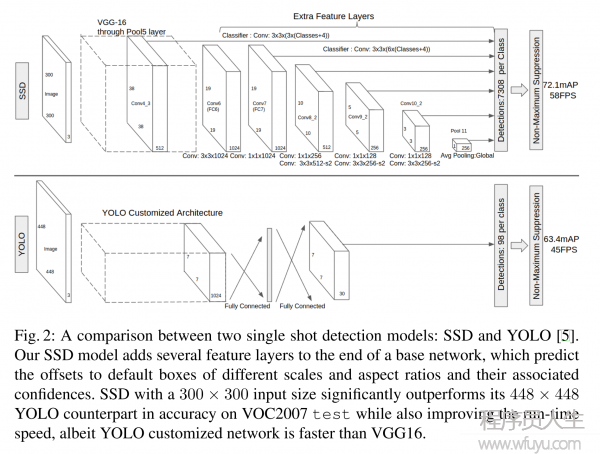
The Single Shot Detector(SSD)
这部份详细讲授了 SSD 物体检测框架,和 SSD 的训练方法。
这里,先弄清楚下文所说的 default box 和 feature map cell 是甚么。看下图:
-
feature map cell 就是将 feature map 切分成 8×8 或 4×4 以后的1个个 格子;
-
而 default box 就是每个格子上,1系列固定大小的 box,即图中虚线所构成的1系列 boxes。

Model
SSD 是基于1个前向传播 CNN 网络,产生1系列 固定大小(fixed-size) 的 bounding boxes,和每个 box 中包括物体实例的可能性,即 score。以后,进行1个 非极大值抑制(Non-maximum suppression) 得到终究的 predictions。
SSD 模型的最开始部份,本文称作 base network,是用于图象分类的标准架构。在 base network 以后,本文添加了额外辅助的网络结构:
-
Multi-scale feature maps for detection
在基础网络结构后,添加了额外的卷积层,这些卷积层的大小是逐层递减的,可以在多尺度下进行 predictions。 -
Convolutional predictors for detection
每个添加的特点层(或在基础网络结构中的特点层),可使用1系列 convolutional filters,去产生1系列固定大小的 predictions,具体见 Fig.2。对1个大小为 m×n,具有 p 通道的特点层,使用的 convolutional filters 就是 3×3×p 的 kernels。产生的 predictions,那末就是归属种别的1个得分,要末就是相对 default box coordinate 的 shape offsets。
在每个 m×n 的特点图位置上,使用上面的 3×3 的 kernel,会产生1个输出值。bounding box offset 值是输出的 default box 与此时 feature map location 之间的相对距离(YOLO 架构则是用1个全连接层来代替这里的卷积层)。 -
Default boxes and aspect ratios
每个 box 相对与其对应的 feature map cell 的位置是固定的。 在每个 feature map cell 中,我们要 predict 得到的 box 与 default box 之间的 offsets,和每个 box 中包括物体的 score(每个种别几率都要计算出)。
因此,对1个位置上的 k 个boxes 中的每个 box,我们需要计算出 c 个类,每个类的 score,还有这个 box 相对 它的默许 box 的 4 个偏移值(offsets)。因而,在 feature map 中的每个 feature map cell 上,就需要有 (c+4)×k 个 filters。对1张 m×n 大小的 feature map,即会产生 (c+4)×k×m×n 个输出结果。
这里的 default box 很类似于 Faster R-CNN 中的 Anchor boxes,关于这里的 Anchor boxes,详细的参见原论文。但是又不同于 Faster R-CNN 中的,本文中的 Anchor boxes 用在了不同分辨率的 feature maps 上。
Training
在训练时,本文的 SSD 与那些用 region proposals + pooling 方法的区分是,SSD 训练图象中的 groundtruth 需要赋予到那些固定输出的 boxes 上。在前面也已提到了,SSD 输出的是事前定义好的,1系列固定大小的 bounding boxes。
以下图中,狗狗的 groundtruth 是红色的 bounding boxes,但进行 label 标注的时候,要将红色的 groundtruth box 赋予 图(c)中1系列固定输出的 boxes 中的1个,即 图(c)中的红色虚线框。
事实上,文章中指出,像这样定义的 groundtruth boxes 不止在本文中用到。在 YOLO 中,在 Faster R-CNN 中的 region proposal 阶段,和在 MultiBox 中,都用到了。
当这类将训练图象中的 groundtruth 与固定输出的 boxes 对应以后,就能够 end-to-end 的进行 loss function 的计算和 back-propagation 的计算更新了。
训练中会遇到1些问题:
-
选择1系列 default boxes
-
选择上文中提到的 scales 的问题
-
hard negative mining
-
数据增广的策略
下面会谈本文的解决这些问题的方式,分为以下下面的几个部份。
Matching strategy:
如何将 groundtruth boxes 与 default boxes 进行配对,以组成 label 呢?
在开始的时候,用 MultiBox 中的 best jaccard overlap 来匹配每个 ground truth box 与 default box,这样就可以保证每个 groundtruth box 与唯1的1个 default box 对应起来。
但是又不同于 MultiBox ,本文以后又将 default box 与任何的 groundtruth box 配对,只要二者之间的 jaccard overlap 大于1个阈值,这里本文的阈值为 0.5。
Training objective:
SSD 训练的目标函数(training objective)源自于 MultiBox 的目标函数,但是本文将其拓展,使其可以处理多个目标种别。用 xpij=1 表示 第 i 个 default box 与 种别 p 的 第 j 个 ground truth box 相匹配,否则若不匹配的话,则 xpij=0。
根据上面的匹配策略,1定有 ∑ixpij≥1,意味着对 第 j 个 ground truth box,有可能有多个 default box 与其相匹配。
总的目标损失函数(objective loss function)就由 localization loss(loc) 与 confidence loss(conf) 的加权求和:
其中:
-
N 是与 ground truth box 相匹配的 default boxes 个数
-
localization loss(loc) 是 Fast R-CNN 中 Smooth L1 Loss,用在 predict box(l) 与 ground truth box(g) 参数(即中心坐标位置,width、height)中,回归 bounding boxes 的中心位置,和 width、height
-
confidence loss(conf) 是 Softmax Loss,输入为每类的置信度 c
-
权重项 α,设置为 1
Choosing scales and aspect ratios for default boxes:
大部份 CNN 网络在越深的层,feature map 的尺寸(size)会愈来愈小。这样做不单单是为了减少计算与内存的需求,还有个好处就是,最后提取的 feature map 就会有某种程度上的平移与尺度不变性。
同时为了处理不同尺度的物体,1些文章,如 ICLR 2014, Overfeat: Integrated recognition, localization and detection using convolutional networks,还有 ECCV 2014, Spatial pyramid pooling in deep convolutional networks for visual recognition,他们将图象转换成不同的尺度,将这些图象独立的通过 CNN 网络处理,再将这些不同尺度的图象结果进行综合。
但是其实,如果使用同1个网络中的、不同层上的 feature maps,也能够到达相同的效果,同时在所有物体尺度中同享参数。
之前的工作,如 CVPR 2015, Fully convolutional networks for semantic segmentation,还有 CVPR 2015, Hypercolumns for object segmentation and fine-grained localization 就用了 CNN 前面的 layers,来提高图象分割的效果,由于越底层的 layers,保存的图象细节越多。文章 ICLR 2016, ParseNet: Looking wider to see better 也证明了以上的想法是可行的。
因此,本文同时使用 lower feature maps、upper feature maps 来 predict detections。下图展现了本文中使用的两种不同尺度的 feature map,8×8 的feature map,和 4×4 的 feature map:
1般来讲,1个 CNN 网络中不同的 layers 有着不同尺寸的 感受野(receptive fields)。所幸的是,SSD 结构中,default boxes 没必要要与每层 layer 的 receptive fields 对应。本文的设计中,feature map 中特定的位置,来负责图象中特定的区域,和物体特定的尺寸。加入我们用 m 个 feature maps 来做 predictions,每个 feature map 中 default box 的尺寸大小计算以下:
上一篇 Flask Web 开发 关注者