Consul入门04 - Consul集群
Part 1:转载自:https://segmentfault.com/a/1190000005040904
我们已启动了我们的第1个代理并且在这个代理上注册和查询了服务。这些显示了使用Consul是多么的容易但是并没有展现Consul的可扩大性和可用于产品级别的服务发现的基础设施。在本篇向导中,我们将建立我们第1个多成员的真实的集群。
当1个Consul代理启动后,它对任何其他的节点都1无所知:它是个单独的隔离集群。为了让它感知其他的集群成员,代理必须加入1个现有的集群中去。为了加入1个现有的集群,它只需要知道1个单个的现有成员。它加入后,代理将广播该成员,并且快速发现集群中的其它成员。1个Consul代理能够加入任何其它的代理,不单单是那些运行在服务模式下的代理。
启动代理
为了摹拟1个相对真实的集群,我们将通过Vagrant启动两个节点的集群。接下来使用的Vagrantfile可以在Consul仓库demo中找到。
我们首先启动两个节点:
$ vagrant up1旦该系统可用了,我们就可以通过ssh登录到该系统,并开始配置我们的集群。我们开始登录到第1个节点:
$ vagrant ssh n1在我们之前的例子里,我们使用 *-dev 标志来快速地设置1个开发服务器。不管如何它其实不能用于1个集群的环境下。我们将移除 -dev* 标志,而是替换成指定的用于集群的标志,下面就回触及该标志。
每一个集群节点都必须有1个唯1的名称。默许下Consul使用计算机的主机名,不过我们可使用 -node 命令行选项手动地覆盖它。
我们也能够指定 绑定地址:Consul将在该地址侦听,并且改地址可以被集群中所有其它的节点访问到。虽然1个 绑定 的地址不是1个严格需要的(Consul将默许侦听在系统中第1个私有的IP),不过最好提供1个。1个生产环境下的服务通常有多个网络接口,所以指定1个 绑定 地址将保证你不会把Consul绑定到毛病的网络接口上。
第1个节点现在将作为我们集群中的唯1服务器,我们指定它运行在server模式下。
-bootstrap-expect 标志暗示Consul服务器我们会有其它的服务节点将会加入。这个标志的目的是延迟复制日志的引导直到预期的服务节点成功加入。你可以在引导教程里查阅到更多的信息。
最后,我们增加 config-dir,指定将在哪里可以找到服务和检查定义。
所有的标志都指定后,将这些设置加入 consul ageng 命令行:
vagrant@n1:~$ consul agent -server -bootstrap-expect 1 \
-data-dir /tmp/consul -node=agent-one -bind=172.20.20.10 \
-config-dir /etc/consul.d
...现在,在另外一终端里,我们连接到第2个节点:
$ vagrant ssh n2这次,我们设置 绑定地址 是第2个节点的IP地址。由于该节点将不会是1个Consul的服务器,所以我们不指定它启动为服务器模式。
所有的标志都指定后,将这些设置加入 consul ageng 命令行:
vagrant@n2:~$ consul agent -data-dir /tmp/consul -node=agent-two \
-bind=172.20.20.11 -config-dir /etc/consul.d
...这时候,我们已有了两个Consul代理在运行:1个服务器和1个客户端。这两个Consul代理现在还对彼此没有任何感知,它们都为两个单节点的集群。你可以运行 consul members 来验证它们,每一个集群都仅包括1个成员。
加入集群
现在,我们将告知第1个代理加入第2个代理,在1个新的终端中运行以下命令:
$ vagrant ssh n1
...
vagrant@n1:~$ consul join 172.20.20.11
Successfully joined cluster by contacting 1 nodes.你应当可以在各自的代理日志中看到1些日志的输出。如果你仔细的查看,你将会看到有节点加入的日志信息。如果你再次运行consul members,你会看到两个代理都已感知到了另外一个节点的存在。
vagrant@n2:~$ consul members
Node Address Status Type Build Protocol
agent-two 172.20.20.11:8301 alive client 0.5.0 2
agent-one 172.20.20.10:8301 alive server 0.5.0 2记住:为了加入1个集群,1个Consul代理只需要知道1个现有的成员。在加入指定的集群后,各个代理睬相互传播完全的成员信息。
启动时自动加入1个集群
理想情况下,不管甚么时候1个新的节点加入了你的数据中心中,它应当自动地加入Consul集群而无需手动操作。为了到达这个目的,你可使用Atlas by HashiCorp并且指定 -atlas-join 标志。下面就是1个配置例子:
$ consul agent -atlas-join \
-atlas=ATLAS_USERNAME/infrastructure \
-atlas-token="YOUR_ATLAS_TOKEN"这需要1个Atlas的用户名和token,在这里创建帐号,然后在你的Consul配置中使用你认证信息的替换各自的值。现在,不管什么时候1个通过Consul代理启动的节点加入,它将自动加入你的Consul集群而无需硬编码任何的配置信息。
另外一个可以选择的是,你可以在启动的时候使用 -join 标志或 start_join 指定1个已知Consul代理的地址来加入1个集群。
查询节点
就像查询服务1样,Consul有1个API用户查询节点信息。你可以通过DNS或HTTP API来查询。
对DNS API,名称结构是 NAME.node.consul 或 NAME.node.DATACENTER.consul。 如果数据中心被移除,Consul将仅仅查询本地数据中心。
例如,从“agent-one”,我们可以查询节点"agent-two"的地址:
vagrant@n1:~$ dig @127.0.0.1 -p 8600 agent-two.node.consul
...
;; QUESTION SECTION:
;agent-two.node.consul. IN A
;; ANSWER SECTION:
agent-two.node.consul. 0 IN A 172.20.20.11这类查找节点的能力对系统管理任务而言是非常有用的。例如知道了节点的地址,我们可使用ssh登录到该节点并且可以非常容易地使得该节点成为Consul集群中的1部份并且查询它。
离开集群
为了离开指定的集群,你可以优雅地退出1个代理(使用 Ctrl-C)或强迫杀死代理进程。优雅地离开可使得节点转换成离开状态;其它情况下,其它的节点检测这个节点将失败。其不同的地方在这里有详细的描写。
下1步
现在有了1个多节点的Consul集群已启动并且运行着。让我们通过[健康检测]()使我们的服务具有更强的鲁棒性。
Part 2:根据Part1、Windows安装Linux虚拟机(CentOS7)及Consul入门01-03,我们使用虚拟机来实现集群(3台:3台机器才能满足基础的集群,当有1台主服务退出时,另外两台重新选举新的主服务)。

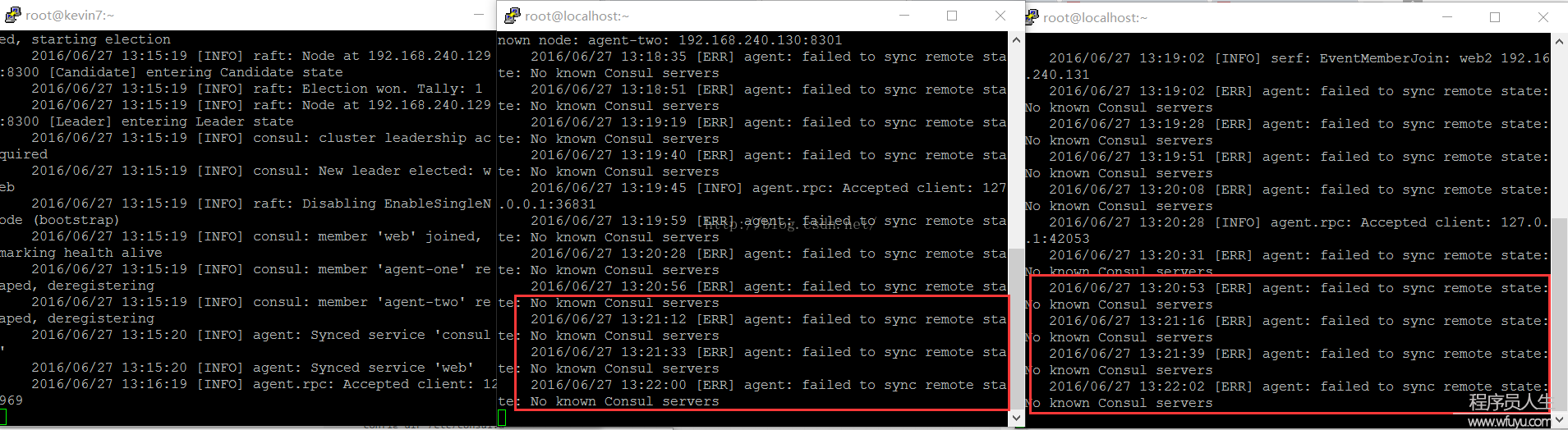
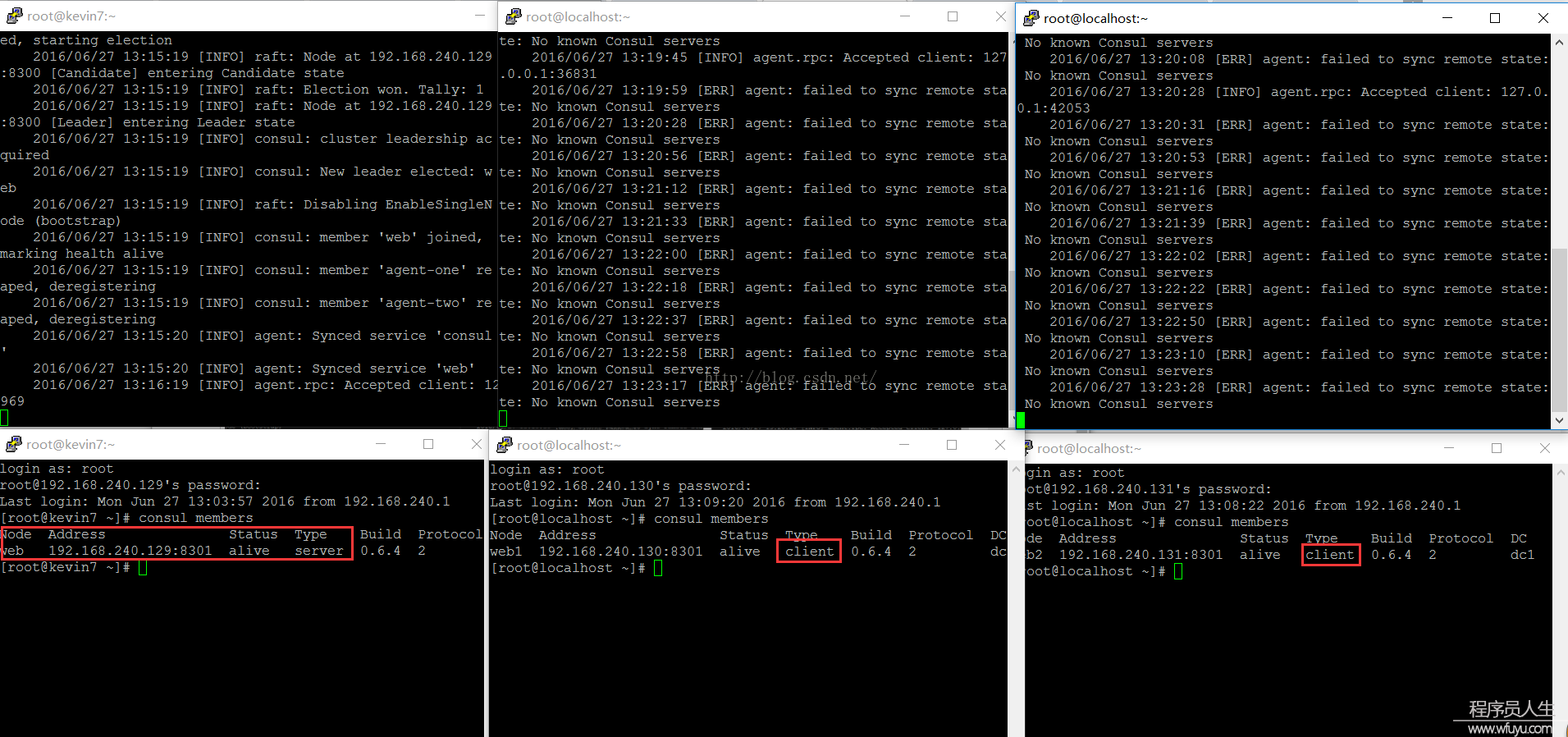
启动1个consul agent ,只是启动1个孤立的node,如果想知道集群中的其他节点,应当将consul agent加入到集群中去 cluster。
agent有两种模式:server与client。server模式包括了1致性的工作:保证1致性和可用性(在部份失败的情况下),响应RPC,同步数据到其他节点代理。
client 模式用于与server进行通讯,转发RPC到服务的代理agent,它仅保存本身的少许1些状态,是非常轻量化的东西。本身是相对无状态的。
agent除去设置server/client模式、数据路径以外,还最好设置node的名称和ip。

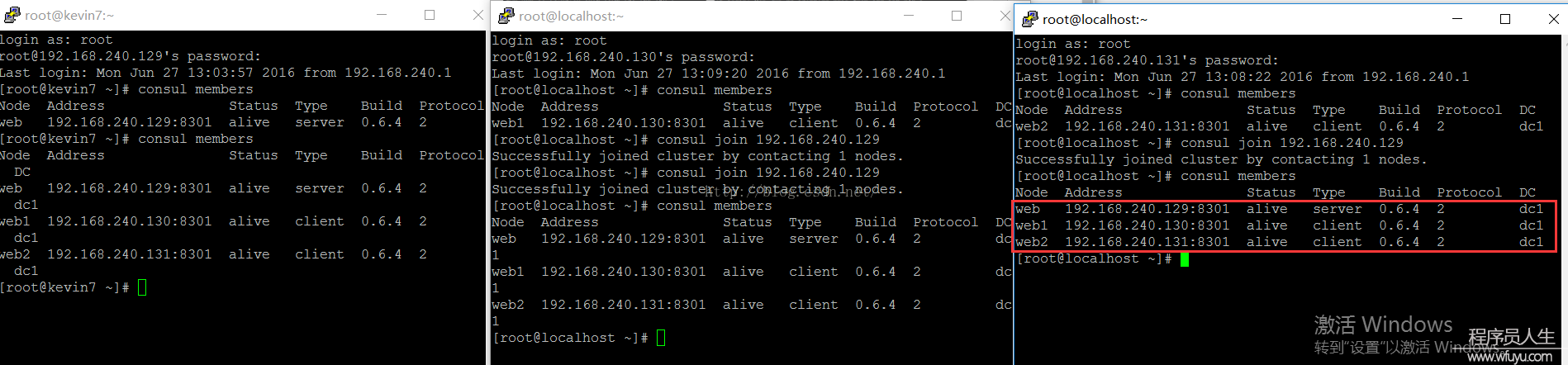
Part 3:Server之间的leader自动选举功能:这次我们需要4台机器,其中web、web1、web2都定义为server,1台client。(虚拟机安装及基本配置请看:Windows安装Linux虚拟机(CentOS7)及Consul入门01-03)
web:
web1、web2:用以下命令启动consul,不需要带bootstrap 选项:
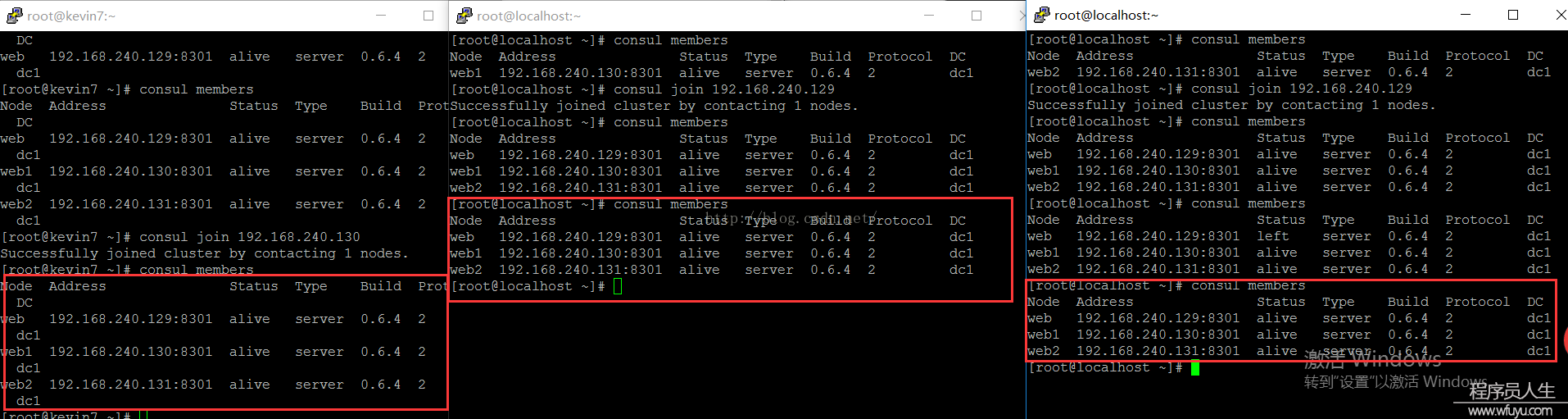
PS:3台server都启动以后,会发现web1和web2在控制台也会有消息更新,提示NO cluster leader,说明没法选举leader,分别查看各自的集群信息时,也是没法相互查看的。
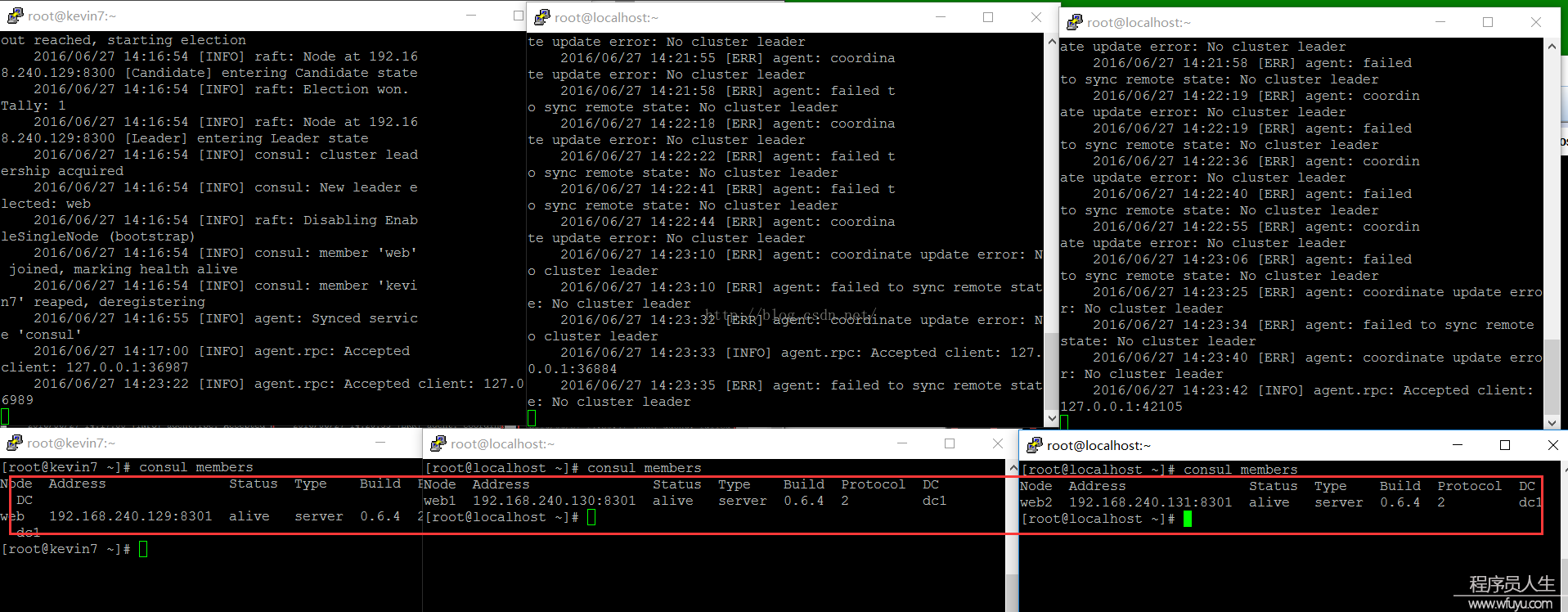
web1、web2需要加入到web的集群中:consul join 192.168.240.129:
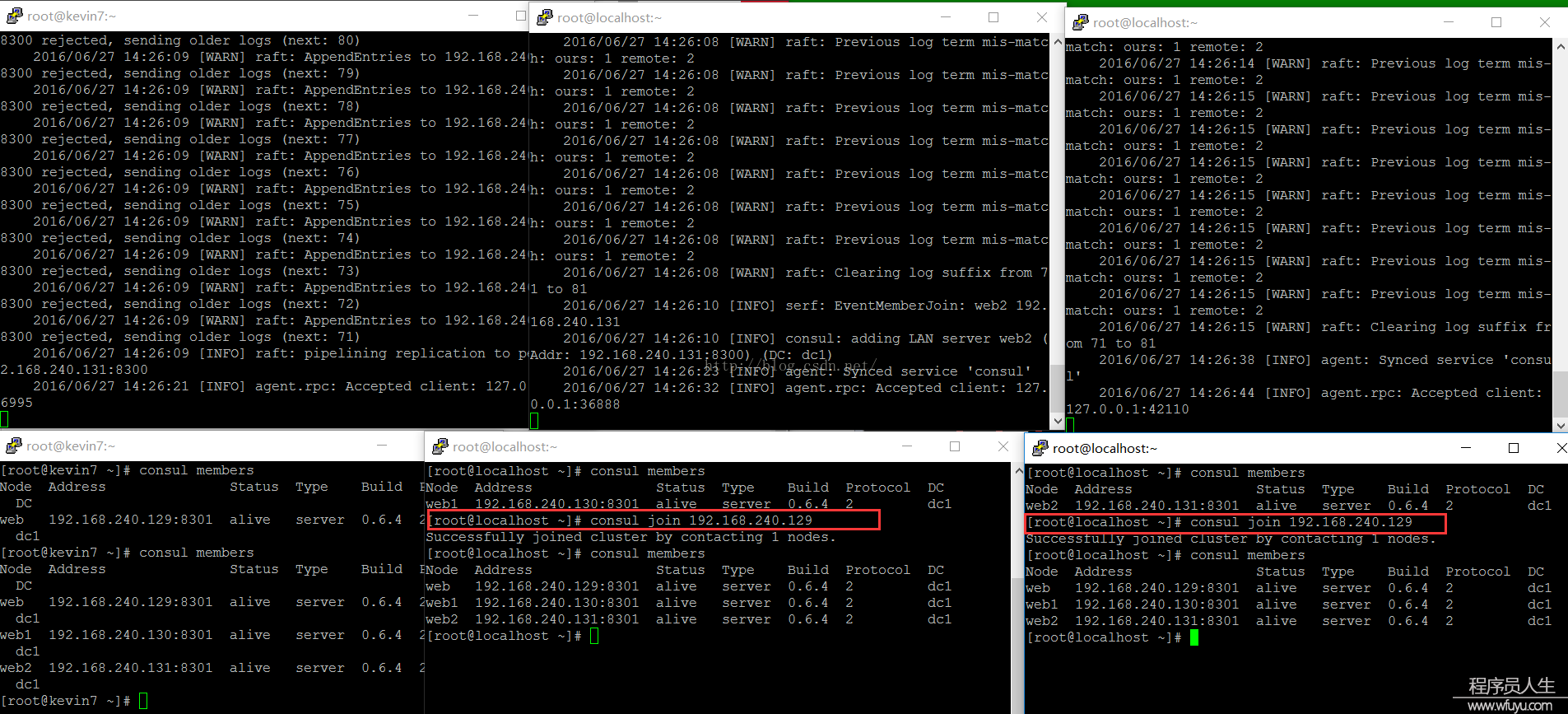
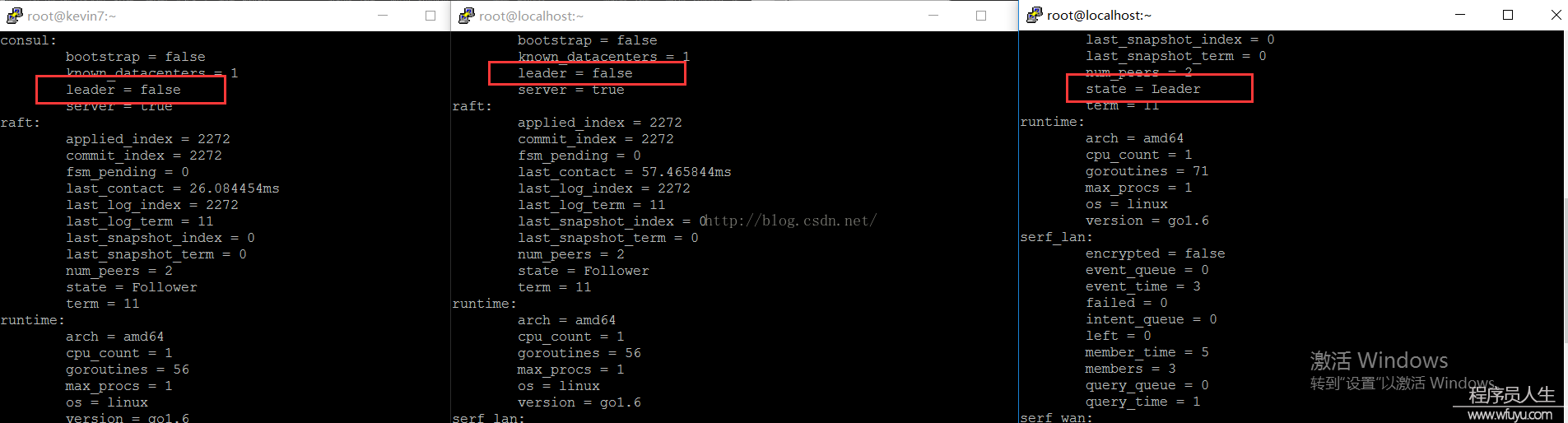
当3台server都加入到集群,我们需要配置这3台机子为同等的server,并且让它们自己选择leader,这时候可以停止第1台(web)的consul,然后运行以下命令: