Flask Web 开发学习稿(二)
第4章 Web 表单
request.from 能获得 POST 要求中提交的表单数据
Flask-WTF 扩大可以把处理 Web 表单的进程变成1种愉悦的体验
4.1 跨站要求捏造保护
默许情况下,Flask-WTF 能保护所有表单免受跨站要求捏造的攻击,为了实现 CSRF 保护,Flask-WTF 需要程序设置1个密钥,会使用这个密钥生成加密令牌,再用令牌验证要求中表单数据的真伪
设置密钥的方法如示例所示
app = Flask(__name__)
app.config['SECRET_KEY'] = 'This is a secret key'app.config字典可用来存储框架、扩大和程序本身的配置变量,这个对象还提供了1些方法可以从文件或环境中导入配置值。SECRTET_KEY 配置变量是通用密钥,可在 Flask 和多个第3方扩大中使用。
为了增强安全性,密钥不应当直接写入代码,而要保存在环境变量中
4.2 表单类
使用 Flask-WTF 时,每一个 Web 表单都由1个继承自 Form 的类表示,这个类定义表单中的1组字段,每一个字段都用对象表示,字段对象可附属1个或多个验证函数
from flask.ext.wtf import Form
from wtforms import StringField, SubmitField
from wtforms.validators import Required
class NameForm(Form):
name = StringField('What is your name?', validators=[Required()])
submit = SubmitField('Submit')表单的每一个属性都定义为类的属性,类变量的值是相应字段类型的对象,StringField 类表示属性为 type="text" 的 元素,SubmitField 类表示属性为 type="submit" 的 元素
字段构造函数的第1个参数是把表单渲染成 HTML 时使用的标号,可选参数 validators 指定1个由验证函数组成的列表,在接受用户提交的数据之前验证数据,验证函数Required()确保提交的字段不为空
Form 基类由 Flask-WTF 扩大定义,所以从 flask.ext.wtf 中导入,字段和验证函数却可以直接从 WTForms 包中导入
| 字段类型 | 说明 |
|---|---|
| StringField | 文本字段 |
| TextAreaField | 多行文本字段 |
| PasswordField | 密码文本字段 |
| HiddenField | 隐藏文本字段 |
| DateField | 值为datatime.date格式 |
| DateTimeField | 值为datatime.datetime格式 |
| IntegerField | 值为整数 |
| DecimalField | 值为decimal.Decimal |
| FloatField | 值为浮点数 |
| BooleanField | 复选框,值为 True 和 False |
| RadioField | 1组单选框 |
| SelectField | 下拉列表 |
| SelectMultipleField | 下拉列表可以多选 |
| FileField | 文件上传字段 |
| SubmitField | 表单提交按钮 |
| FormField | 把表单作为字段嵌入另外一个表单 |
| FieldList | 1组指定类型的字段 |
WTForms 内建的验证函数以下表所示
| 验证函数 | 说明 |
|---|---|
| 验证电子邮件地址 | |
| EqualTo | 比较两个字段的值,经常使用于密码确认 |
| IPAddress | 验证IPv4网络地址 |
| Length | 验证输入字符串的长度 |
| NumberRange | 验证输入的值在数字范围内 |
| Optional | 无输入值时跳过其他验证函数 |
| Required | 确保字段中有数据 |
| Regexp | 使用正则表达式验证输入值 |
| URL | 验证URL |
| AnyOf | 确保输入值在可选值列表中 |
| NoneOf | 确保输入值不在可选值列表中 |
4.3 把表单渲染成HTML
在 index.html 中
{% extends "base.html" %}
{% import "bootstrap/wtf.html" as wtf %}
{% block title %}Flasky{% endblock %}
{% block page_content %}
<div class="page-header">
<h1>Hello, {% if name %}{{ name }}{% else %}Stranger{% endif %}!</h1>
</div>
{{ wtf.quick_form(form) }}
{% endblock %}import 允许导入模版中的元素并用在多个模版中,导入的 bootstrap/wtf.html 文件中定义了1个使用 Bootstrap 渲染 Flask-WTF 表单对象的辅助函数。
wtf.quick_form() 函数的参数为 Flask-WTF 表单对象,使用 Bootstrap 的默许样式渲染传入的表单
该文件中使用了模版条件语句,在 Jinja2 中的条件语句格式为{% if condition %}...{% else %}...{% endif %},如果条件的计算结果为 True,那末渲染 if 和 else 指令之间的值,如果为 False,则渲染 else 和 endif 指令之间的值。此处,如果没有模版变量 name 就渲染字符串 Stranger。
下面使用 wtf.quick_form() 函数渲染 NameForm 对象
4.4 在视图函数中处理表单

在使用了 manager.run() 以后,启动的方式有所变化,必须附加参数 runserver,如上图所示
from flask import Flask, render_template
from flask.ext.script import Manager
from flask.ext.bootstrap import Bootstrap
from flask.ext.moment import Moment
from flask.ext.wtf import Form
from wtforms import StringField, SubmitField
from wtforms.validators import Required
app = Flask(__name__)
app.config['SECRET_KEY'] = 'hard to guess string'
manager = Manager(app)
bootstrap = Bootstrap(app)
moment = Moment(app)
class NameForm(Form):
name = StringField('What is your name?', validators=[Required()])
submit = SubmitField('Submit')
![icone.png-22.2kB][1]
@app.errorhandler(404)
def page_not_found(e):
return render_template('404.html'), 404
@app.errorhandler(500)
def internal_server_error(e):
return render_template('500.html'), 500
@app.route('/', methods=['GET', 'POST'])
def index():
name = None
form = NameForm()
if form.validate_on_submit():
name = form.name.data
form.name.data = ''
return render_template('index.html', form=form, name=name)
if __name__ == '__main__':
manager.run()index.html 沿用上1小节的便可,运行后可以得到以下页面
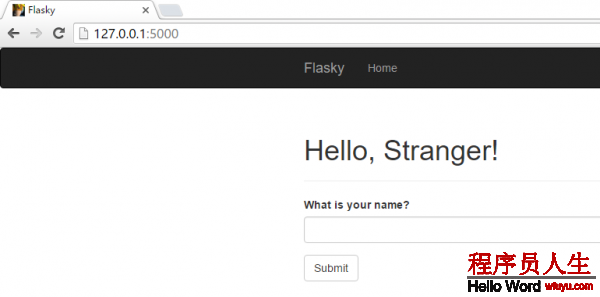
methods 通知 Flask 在 URL 映照中把这个视图函数注册为 GET 和 POST 要求的处理程序,如果没指定 methods 参数,只会注册为 GET 要求的处理程序
在视图函数中创建1个 NameForm 类实例用于表示表单,如果数据能被所有的验证函数接受,那末form.validate_on_submit() 的返回值为 True,这个函数的返回值决定是重新渲染表单还是处理表单提交的数据
1个要求的详解:**用户提交表单后,1个 POST 要求过来,validate_on_submit() 会调用 name 字段上附属的 Required() 验证函数,如果名字不为空就可以通过验证,函数返回 True。
用户输入的名字通过字段的 data 属性获得,在 if 语句中把名字赋值给局部变量 name,再把 data 属性置为空字符串,从而清空表单字段**
如果提交表单时,没有填入内容, Required 验证函数会捕获毛病并显示提示,良好的扩大让程序具有更加强大的功能
4.5 重定向和用户会话
当我过1段时间后点击了刷新按钮时,阅读器会弹出提示询问我是不是想要重新提交表单,由于阅读器发出的最后1个要求是 POST 要求。
使用重定向作为 POST 要求的响应,而不是使用常规响应可以规避这个问题,但是如此这般又引入了新问题。使用 form.name.data 获得用户输入的名字,在要求结束时数据丢失。这里我们需要用到用户会话,把数据存储在用户会话中,在要求之间记住数据
默许情况下,用户会话保存在客户端 Cookie 中,使用设置的 SECRET_KEY 进行加密签名,如果篡改了 Cookie 中的内容,签名就会失效,会话也就失效了
def index():
form = NameForm()
if form.validate_on_submit():
session['name'] = form.name.data
return redirect(url_for('index'))
return render_template('index.html', form=form, name=session.get('name'))修改其视图函数就能够完成功能,之前的名字被保存在局部变量中,现在保存在用户会话里,在需要的时候可以取出使用
redirect() 是个辅助函数,用来生成 HTTP 重定向响应,重定向可以写根地址也能够使用 URL 生成函数 url_for(),推荐使用生成函数生成 URL,这样保证了 URL 和定义的路由兼容,而且修改路由名字后仍然可用
url_for() 函数的唯逐一个必须指定的参数是端点名,即路由的内部名字,默许情况下,路由的端点是相应视图函数的名字
4.6 Flash 消息
提示消息使用flash()函数实现
def index():
form = NameForm()
if form.validate_on_submit():
old_name = session.get('name')
if old_name is not None and old_name != form.name.data:
flash('Looks like you have changed your name!')
session['name'] = form.name.data
return redirect(url_for('index'))
return render_template('index.html', form=form, name=session.get('name'))将视图函数修改成上面这样便可
仅调用flash()函数其实不能把消息显示出来,程序使用的模版要渲染这些消息,最好在基模版中渲染 Flash 消息,这样所有页面都能使用这些消息, Flask 把get_flashed_messages()函数开放给模版,用来获得并渲染消息,将base.html修改以下
{% extends "bootstrap/base.html" %}
{% block title %}Flasky{% endblock %}
{% block head %}
{{ super() }}
<link rel="shortcut icon" href="{{ url_for('static', filename='favicon.ico') }}" type="image/x-icon">
<link rel="icon" href="{{ url_for('static', filename='favicon.ico') }}" type="image/x-icon">
{% endblock %}
{% block navbar %}
<div class="navbar navbar-inverse" role="navigation">
<div class="container">
<div class="navbar-header">
<button type="button" class="navbar-toggle" data-toggle="collapse" data-target=".navbar-collapse">
<span class="sr-only">Toggle navigation</span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a class="navbar-brand" href="/">Flasky</a>
</div>
<div class="navbar-collapse collapse">
<ul class="nav navbar-nav">
<li><a href="/">Home</a></li>
</ul>
</div>
</div>
</div>
{% endblock %}
{% block content %}
<div class="container">
{% for message in get_flashed_messages() %}
<div class="alert alert-warning">
<button type="button" class="close" data-dismiss="alert">×</button>
{{ message }}
</div>
{% endfor %}
{% block page_content %}{% endblock %}
</div>
{% endblock %}
{% block scripts %}
{{ super() }}
{{ moment.include_moment() }}
{% endblock %}第5章 数据库
5.1 NoSQL 数据库
NoSQL 数据库1般使用集合代替表,使用文档代替记录
5.2 Python 数据库框架
易用性
数据库抽象层,又被称作object-relational mappers (ORMs) 或 object-document mappers (ODMs),提供了从高级对象到低级数据库实体的直接转换,使用起来固然会更加方便。性能
ORMs和ODMs把对象转化为数据库实体会有1些开消,但多数时候这个开消可以疏忽不计的。通常来讲,使用ORMs和ODMs带来的工作效能提升常常大于所带来的性能消耗,因此我们没有甚么理由谢绝ORMs和ODMs。通常比较公道的做法是用数据库抽象层来做经常使用的操作,而只在某些需要特别优化的地方使用原生的数据库操作。可移植性
所选择的数据库在生产和部署环境下是不是可用是1个必须斟酌的因素,比如你想要把你的利用部署在云平台上,你固然应当首先知道该平台支持哪些数据库。
ORMs和ODMs还能带来的其他1个便利。虽然多数数据库提供了1个抽象层,但是还有1些更高阶的抽象层提供了只用1套接口便可操作多种数据库的功能。最好的例子就是SQLAlchemy ORM,它提供了1系列关系型数据库引擎的支持,比如MySQL、Postgres 和 SQLite。- Flask 集成度
虽然不是必须要求能和Flask集成,但是能和Flask集成意味着能为你省去你大量书写代码的时间 。正是由于使用Flask集成的数据库引擎能简化配置和操作,你应当尽量选择Flask扩大情势的数据库引擎包。综上,本书将会选择Flask-SQLAlchemy作为数据库工具,它是1个基于SQLAlchemy的Flask扩大。
本书选择了 Flask-SQLAlchemy
5.3 使用 Flask-SQLAlchemy 管理数据库
使用 pip install flask-sqlalchemy 来安装 Flask-SQLAlchemy
Flask-SQLAlchemy 数据库使用 URL 指定,流行的数据库 URL 指定表以下
| 数据库引擎 | URL |
|---|---|
| MySQL | mysql://username:password@hostname/database |
| Postgres | postgresql://username:password@hostname/database |
| SQLite(Unix) | sqlite:////absolute/path/to/database |
| SQLite(Windows) | sqlite:///c:/absolute/path/to/database |
hostname 是数据库服务所在的主机,database 指定使用的数据库名,username 和 password 表示数据库密令
程序使用的数据库 URL 被在配置在 Flask 的 config 对象的 SQLALCHEMY_DATABASE_URI 中,还有另外一个重要的属性被配置在 SQLALCHEMY_COMMIT_ON_TEARDOWN 中用来在每次要求结束时候自动提交数据库改动,Flask-SQLAlchemy 官方文档提供了更多配置选项。以下是1个配置 SQLite 数据库的例子:
from flask.ext.sqlalchemy import SQLAlchemy
basedir = os.path.abspath(os.path.dirname(__file__))
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = \
'sqlite:///C:\\Users\\Avenger\\Desktop\\test\\database.db'
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
db = SQLAlchemy(app)千万设置好['SQLALCHEMY_DATABASE_URI']这1行,否则会报错,注意 Windows 下是3个/
模型是指那些在程序中被持久化的对象,在 ORM 的环境下,1个模型是1个典型的 Python 类,类中的属性对应数据库表中的列。
Flask-SQLAlchemy 数据库的实例提供了1个 model 的基类和1系列的工具方法方法来定义他们的结构,在前面示例中的 roles 和 users 表可以定义成以下的 Role 和 User models
class Role(db.Model):
__tablename__ = 'roles'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
def __repr__(self):
return '<Role %r>' % self.name
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, index=True)
def __repr__(self):
return '<User %r>' % self.username类变量 __tablename__ 定义在数据库中使用的表名,如果没有定义 __tablename__ 会被指定1个默许的名字,推荐自己来命名。其余的类变量都是该模型的属性,被定义为 db.Column
db.Column 类构造函数的第1个参数是数据库列和模型属性的类型,其余的参数指定属性的配置选项,以下表所示
这两个模型都定义了 __repr()__ 方法,返回1个具有可读性的字符串表示模型,可在调试时使用
最经常使用的列类型
| 类型名 | Python 类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,1般是32位 |
| SmallInteger | int | 取值范围小的整数,1般是16位 |
| BigInteger | int or long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 定点数 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长 Unicode 字符串 |
| UnicodeText | unicode | 变长 Unicode 字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 日期 |
| Time | datetime.time | 时间 |
| DateTime | datetime.datetime | 日期和时间 |
| Interval | datetime.timedelta | 时间间隔 |
| Enum | str | 1组字符串 |
| PickleType | Any Python object | 自动使用 Pickle 序列化 |
| LargeBinary | str | 2进制文件 |
最经常使用的列选项
| 选项名 | 说明 |
|---|---|
| primary_key | 如果设为 True,这列就是表的主键 |
| unique | 如果设为 True,这列不允许出现重复值 |
| index | 如果设为 True,为这列创建索引,提升查询效力 |
| nullable | 如果设为 True,这列允许使用空值,如果设为 False,这列不允许使用空值 |
| default | 为这列设定默许值 |
Flask-SQLAlchemy 要求每一个模型都要定义主键,这1列常常命名为 id
5.4 关系
1对多关系在模型类中的表示方法以下
class Role(db.Model):
__tablename__ = 'roles'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
users = db.relationship('User', backref='role')
def __repr__(self):
return '<Role %r>' % self.name
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, index=True)
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
def __repr__(self):
return '<User %r>' % self.username关系使用 users 属性代表这个关系的面向对象视角,对1个 Role 类的实例,其 users 属性将返回
"users = db.relationship('User', backref='role')" 代表这个关系的面向对象的视图。能返回指定角色的相干人员列表。当外键由多个组成时,还需要斟酌1些其他参数:
| 选项名 | 说明 |
|---|---|
| backref | 在关系的另外一个模型中添加反向援用 |
| primaryjoin | 明确指定两个模型之间使用的联结条件,只在模棱两可的关系中需要指定 |
| lazy | 指定如何加载相干记录,详细见附表 |
| uselist | 如果设为 False 不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定多对多关系中关系表的名字 |
| secondaryjoin | SQLAlchemy 没法自行决定时,指定多对多关系中的2级联结条件 |
附表
| 可选值 | 说明 |
|---|---|
| select | 首次访问时按需加载 |
| immediate | 源对象加载后就加载 |
| joined | 加载记录,使用联结 |
| subquery | 立即加载,使用子查询 |
| noload | 永不加载 |
| dynamic | 不加载记录,但提供加载记录的查询 |
5.5 数据库操作
5.5.1 创建表 & 插入行
if __name__ == '__main__':
db.create_all()
admin_role = Role(name='Admin')
mod_role = Role(name='Moderator')
user_role = Role(name='User')
user_john = User(username='john', role=admin_role)
user_susan = User(username='susan', role=user_role)
user_david = User(username='david', role=user_role)
manager.run()db.create_all()用来创建数据库,以后的语句都是插入行(在 Role 表和 users 表中)
我们在 SQLiteStudio 来连接这个数据库看是不是创建成功
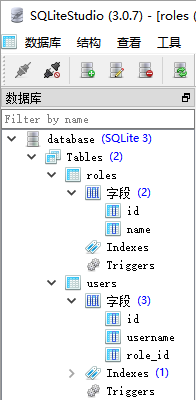
可以发现这个表和列都已创建OK了,但是此时这些对象其实不是真实的数据库内容,只在 Python 中,还未写入数据库,因此 id 等都还没有赋值
db.session.add(admin_role)
db.session.add(mod_role)
db.session.commit()可使用这类方法来写入数据库,commit() 之前都是将对象添加到会话中,commit() 来提交这个会话就能够写入数据库了。添加对象到会话时,我们可简写为以下
db.session.add_all([admin_role, mod_role, user_role,user_john, user_susan, user_david])
db.session.commit()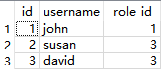
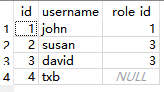
可以直接看出,相干数据已写入了数据库中
使用把相干改动放在会话中提交,在写入会话时产生毛病,全部会话都会失效,这样可以免由于部份更新而致使数据库不1致
数据库会话也能够回滚,db.session.rollback()可以把添加到数据库会话中的所有对象都还原到初始状态
5.5.2 修转业 & 删除行
在数据库会话中调用 add() 方法也能更新模型,使用 delete() 可以删除
if __name__ == '__main__':
db.create_all()
admin_role = Role(name='Admin')
mod_role = Role(name='Moderator')
user_role = Role(name='User')
user_john = User(username='john', role=admin_role)
user_susan = User(username='susan', role=user_role)
user_david = User(username='david', role=user_role)
db.session.add_all([admin_role, mod_role, user_role, user_john, user_susan, user_david])
db.session.commit()
admin_role.name = 'Administrator'
db.session.add(admin_role)
db.session.delete(mod_role)
db.session.commit()
manager.run()在原有项目上测试,会遇到问题,不能重新更新原来的值,重新创建1个空文件连接数据库写入就行了,简单粗鲁的办法
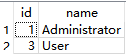
可以看出,更新和删除操作都已可以履行了!插入、删除、更新都必须提交数据库会话才能履行。
5.5.3 查询行
Role.query.all()
User.query.all()
User.query.filter_by(role=user_role).all()
str(User.query.filter_by(role=user_role))
user_role = Role.query.filter_by(role=user_role)每一个模型都有 query 对象,使用过滤器可以配置 query 对象进行更精确的数据库查询,第3个就是查询角色为“user”的所有用户,第4条是查看SQLAlchemy为查询生成的原生 SQL 语句
user_role = Role.query.filter_by(name='User').first() 可以查询名为 User 的用户角色。多个过滤器可以1起调用来获得所需结果
经常使用过滤器:
| 过滤器 | 说明 |
|---|---|
| filer() | 把过滤器添加到原查询上,返回1个新查询 |
| filter_by() | 把等值过滤器添加到原查询上,返回1个新查询 |
| limit() | 使用指定的值限制原查询结果返回的结果数量,返回1个新查询 |
| offset() | 偏移原查询返回的结果,返回1个新查询 |
| order_by() | 根据指定条件对原查询结果进行排序,返回1个新查询 |
| group_by() | 根据指定条件对原查询结果进行分组,返回1个新查询 |
在查询上利用了过滤器后,通过调用all()履行查询,以列表的情势返回结果,全部查询方法以下
| 过滤器 | 说明 |
|---|---|
| all() | 以列表情势返回查询的所有结果 |
| first() | 返回查询的第1个结果,如果没有结果,返回 None |
| first_or_404() | 返回查询的第1个结果,如果没有结果,终止要求,返回 404 响应毛病 |
| get() | 返回指定主键对应的行,如果没有对应的行,返回 None |
| get_or_404() | 返回指定主键对应的行,如果没有指定的主键,终止要求,返回 404 响应毛病 |
| count() | 返回查询结果的数量 |
| paginate() | 返回1个 Paginate 对象,它包括指定范围内的结果 |
下面这个例子分别从关系的两端查询角色和用户之间的1对多关系
users = user_role.users
在履行 user_role.users 时,隐含的查询会调用 all() 返回1个用户列表, query 对象是隐藏的,因此没法指定更精确的查询过滤器,改进以下我们可以通过修改关系的设置,加入lazy = 'dynamic' 参数,从而制止自动履行查询
class Role(db.Model)
#...
users = db.relationship('User', backref='role', lazy='dynamic')
#...这样配置关系后,users = user_role.users 会返回1个还没有履行的查询,因此可以在其上添加过滤器了
user_role.users.order_by(User.username).all()
user_role.users.count()5.6 在视图函数中操作数据库
修改视图函数以下
@app.route('/', methods=['GET', 'POST'])
def index():
form = NameForm()
if form.validate_on_submit():
# 对提交上上来的表单查看数据库中是不是已存在
user = User.query.filter_by(username=form.name.data).first()
if user is None:
# 如果在数据库中不存在,提交进数据库会话中
user = User(username=form.name.data)
db.session.add(user)
session['known'] = False
else:
# 存在的用户,在网站会话中给出已知,用于在 index.html 中进行判断
session['known'] = True
# 用表单中的名字刷新网站会话
session['name'] = form.name.data
return redirect(url_for('index'))
return render_template('index.html', form=form, name=session.get('name'),
known=session.get('known', False))在启动这个 app 之前,需要初始化这个数据库嘛,在 manager.run() 之前,
if __name__ == '__main__':
db.create_all()
admin_role = Role(name='Admin')
mod_role = Role(name='Moderator')
user_role = Role(name='User')
user_john = User(username='john', role=admin_role)
user_susan = User(username='susan', role=user_role)
user_david = User(username='david', role=user_role)
db.session.add_all([admin_role, mod_role, user_role, user_john, user_susan, user_david])
db.session.commit()
admin_role.name = 'Administrator'
db.session.add(admin_role)
db.session.delete(mod_role)
db.session.commit()
print(Role.query.all())
print(User.query.all())
print(User.query.filter_by(role=user_role).all())
print(str(User.query.filter_by(role=user_role)))
print(user_role.users.order_by(User.username).all())
manager.run()index.html 也需要修改,以下
{% extends "base.html" %}
{% import "bootstrap/wtf.html" as wtf %}
{% block title %}Flasky{% endblock %}
{% block page_content %}
<div class="page-header">
<h1>Hello, {% if name %}{{ name }}{% else %}Stranger{% endif %}!</h1>
{% if not known %}
<p>Pleased to meet you!</p>
{% else %}
<p>Happy to see you again!</p>
{% endif %}
</div>
{{ wtf.quick_form(form) }}
{% endblock %}运行以后,在首页提交表单,可以看到提交的名字成功被插入到了数据库中
再次提交这个名字的话,就会看到Happy to see you again!的欢迎提示
5.7 集成 Python Shell
from flask.ext.script import Manager, Shelldef make_shell_context():
return dict(app=app, db=db, User=User, Role=Role)manager.add_command("shell", Shell(make_context=make_shell_context))在 Python 脚本中,增加上述语句,可让 Flask-Script 的 shell 命令自动导入特定的对象,若想把对象添加到导入列表中,我们要为 shell 命令注册1个 make_context 回调函数
make_shell_context() 函数注册了程序、数据库实例和模型,因此这些对象能直接导入 shell
履行 python hello.py shell 就引入了这些对象
5.8 使用 Flask-Migrate 进行数据迁移
更新表的唯1方法就是删除旧表 db.drop_all()
更新表的更好办法是使用数据库迁移框架, SQLAlchemy 的研发了1个叫做 Alembic,也能够使用 Flask-Migrate 扩大,这个扩大轻量级包装了 Alembic
5.8.1 创建迁移仓库
首先进行安装 pip install flask-migrate
再进行初始化:
导入:from flask.ext.migrate import Migrate, MigrateCommand
初始化:
migrate = Migrate(app, db)
manager.add_command('db', MigrateCommand)为了导出数据库迁移指令,Flask-Migrate 提供了1个 MigrateCommand 类,可附加到 Flask-Script 的 manager 对象中

修改脚本参数如上如所示,运行可得

在脚本的目录下创建了 migrations 文件夹,所有迁移脚本都寄存在其中
数据库迁移仓库中的文件要和程序的其他文件1起纳入版本控制
5.8.2 创建迁移脚本
在 Alembic 中,数据库迁移用迁移脚本表示。脚本中有两个函数,分别是 upgrade() 和 downgrade()。 upgrade() 函数把迁移中的改动利用到数据库中, downgrade() 函数则将改动删除。 Alembic 具有添加和删除改动的能力,因此数据库可重设到修改历史的任意1点。
我们可使用 revision 命令手动创建 Alembic 迁移,也可以使用 migrate 命令自动创建。手动创建的迁移只是1个骨架, upgrade() 和 downgrade() 函数都是空的,开发者要使用Alembic 提供的 Operations 对象指令实现具体操作。自动创建的迁移会根据模型定义和数据库当前状态之间的差异生成 upgrade() 和 downgrade() 函数的内容。
自动创建的迁移不1定总是正确的,自动生成迁移脚本后1定要进行检查
python hello.py db migrate -m "initial migration" 自动创建迁移脚本的 migrate 命令
5.8.3 更新数据库
检查并修正好迁移脚本后,我们可使用 db upgrade 命令把迁移利用到数据库中
第1个迁移的作用和调用 db.create_all() 方法1样,但在后面的迁移中 upgrade 可以把改动利用到数据库中,且不影响其中保存的数据
书中说数据库的名字是 data.sqlite 但是我没有成功,我的数据库的名字是 database.db 应当没有区分,只是提起
上一篇 如何添加网络打印机