Hadoop(七)――子项目Hive
前边我们介绍了Hadoop项目的两大基础支柱HDFS和MapReduce,随后又介绍了子项目Pig:1种用类似于SQL的、面向数据流的语言对HDFS下的数据进行处理的MapReduce上层客户端,这大大满足了那些不会Java,不会写MapReduce的程序员。但是对那些之前1直从事Oracle等关系型数据库数据分析的数据分析师,DBA等,还是有些辣手的。而Hadoop的另外一个子项目Hive则解决了这个问题。
好,先看下这篇博客的脉络图:
1,Hive的概念:Hive是基于Hadoop的1个数据仓库工具,可以将结构化的数据文件映照为1张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习本钱低,可以通过类SQL语句(Hive QL)快速实现简单的MapReduce统计,没必要开发专门的MapReduce利用,10分合适数据仓库的统计分析。 我们可以将其看作是从SQL到MapReduce的映照器。
2,Hive的安装:首先要知道Hive将HDFS中的数据组织为表,通过这类方式为HDFS数据赋予结构,而这些数据(例如表模式)称之为Hive的元数据,其寄存在metastore中。根据metastore寄存位置不同,我们可以分为3种安装模式:
1,内嵌模式:metastore服务和Hive服务运行在同1个JVM中,包括1个内嵌的以本地磁盘作为存储的Derby数据库实例。此种安装简单,适用于学习,只允许1个会话连接。
2,本地独立模式:将元数据寄存在独立的数据库中,MySql是很受欢迎的选择,利用metastore服务连接到本地安装的MySql数据库中,支持多会话多用户连接。
3,远程模式:元数据放置在远程的MySql数据库中,这样1个或多个metastore服务和Hive服务运行在不同的进程内。
好,Hive的安装是子项目里边比较简单的,这里看下的内嵌模式的安装:
A,下载并解压到用户目录下:
tar xzf ./apache-hive⑴.2.1-bin.tar.gz
解压的目录和其它项目都是类似的,不再讲述:
B,设置环境变量:
exportHIVE_HOME=/home/ljh/apache-hive⑴.2.1-bin
exportPATH=$PATH:$HIVE_HOME/bin
exportCLASSPATH=$CLASSPATH:$HIVE_HOME/bin
C,配置文件设置:
c.1,hive-env.sh
复制: cp hive-env.sh.template hive-env.sh
设置hadoop_home:HADOOP_HOME=/home/ljh/hadoop⑴.2.1
设置hive的配置文件路径:export HIVE_CONF_DIR=/home/ljh/apache-hive⑴.2.1-bin/conf
c.2,hive-site.xml
复制:cp hive-default.xml.template hive-site.xml
注意:内嵌模式这里不怎样需要配置,如果是独立模式,远程模式,则需要对mysql等进行配置,我们可以通过baidu,google进行各项参数的了解。
D,启动hive:
./hive便可。
其它方式安装参考:
http://sishuok.com/forum/blogPost/list/6221.html
http://blog.csdn.net/xqj198404/article/details/9109715
3,经常使用sql语句进行操作Hive,无在意表的创建,删除,数据的增查(删和改其实都是增的操作),特点和里边的数据类型看这篇博客:http://blog.csdn.net/chenxingzhen001/article/details/20901045
1,建表:create tabletest(id string ,name string)
ROW FORMAT DELIMITED FIELDSTERMINATED BY |
STORED AS TEXTFILE
2,将HDFS中的数据文件加载的表中:
LOAD DATA LOCAL INPATH ./examples/files/test.txt OVERWRITE INTO TABLE test;
3,将查询结果插入到表中,两个hive表中的数据进行过滤插入:
insert overwrite tabletest2 select id,name from test where idis not null;
4,查询:select id ,name from test;
5,表连接:select test.id test1,name from test join test1 on(test.id=test1.id);
这里只是简单的操作,具体的Hive的sql语法,可以参考这篇文章,写的很好很全面:
http://www.cnblogs.com/HondaHsu/p/4346354.html
4,Hive的体系架构:最经典的1张图:
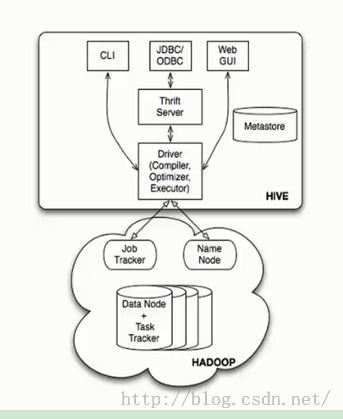
4.1,基本组成:
?用户接口,包括CLI,JDBC/ODBC,WebUI
?元数据存储,通常是存储在关系数据库如mysql, derby 中