百度面试题1、海量日志数据,提取出某日访问百度次数最多的那个IP。
IP 是32位的,最多有个2^32个IP。一样可以采取映照的方法,比如模1000,把全部大文件映照为1000个小文件,再找出每一个小文中出现频率最大的 IP(可以采取hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即 为所求。
百度面试题2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每一个查询串的长度为1⑵55字节。
假定目前有1千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。1个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
第 1步借用hash统计进行预处理: 先对这批海量数据预处理(保护1个Key为Query字串,Value为该Query出现次数,即Hashmap(Query,Value),每次读取1 个Query,如果该字串不在Table中,那末加入该字串,并且将Value值设为1;如果该字串在Table中,那末将该字串的计数加1便可。终究我 们在O(N)(N为1千万,由于要遍历全部数组1遍才能统计处每一个query出现的次数)的时间复杂度内用Hash表完成了统计;
第2步借用堆排序找出最热门的10个查询串:时间复杂度为N'*logK。保护1个K(该题目中是10)大小的小根堆,然后遍历3百万个Query,分别和根元素进行对照(对照value的值),找出10个value值最大的query
终究的时间复杂度是:O(N) + N'*O(logK),(N为1000万,N’为300万)
或:采取trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。
我们先看HashMap 实现
1. HashMap的数据结构
数据结构中有数组和链表来实现对数据的存储,但这二者基本上是两个极端。
数组
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的2分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
链表
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
哈希表
那末我们能不能综合二者的特性,做出1种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表。哈希表((Hash table)既满足了数据的查找方便,同时不占用太多的内容空间,使用也10分方便。
哈希表有多种不同的实现方法,我接下来解释的是最经常使用的1种方法―― 拉链法,我们可以理解为“链表的数组”
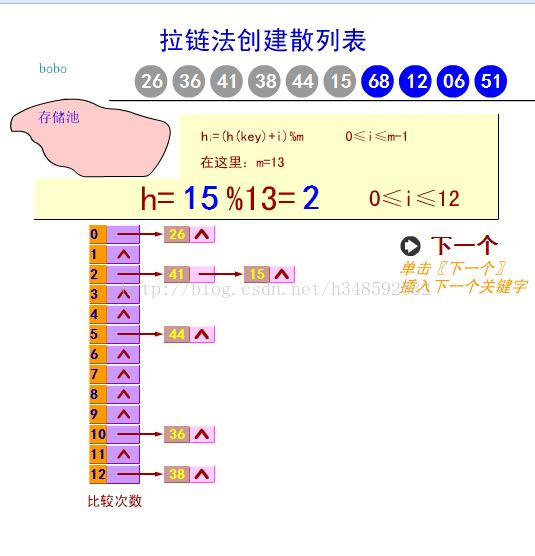
我用java 自己实现了1个HashMap,固然这比较简点,不过能说明大概原理,改有的功能基本上有了
index=hashCode(key)=key%16
哈希算法很多,下面我用了java自带的,固然你也能够用别的
/**
* 自定义 HashMap
* @author JYC506
*
* @param <K>
* @param <V>
*/
public class HashMap<K, V> {
private static final int CAPACTITY = 16;
transient Entry<K, V>[] table = null;
@SuppressWarnings("unchecked")
public HashMap() {
super();
table = new Entry[CAPACTITY];
}
/* 哈希算法 */
private final int toHashCode(Object obj) {
int h = 0;
if (obj instanceof String) {
return StringHash.toHashCode((String) obj);
}
h ^= obj.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/*放入hashMap*/
public void put(K key, V value) {
int hashCode = this.toHashCode(key);
int index = hashCode % CAPACTITY;
if (table[index] == null) {
table[index] = new Entry<K, V>(key, value, hashCode);
} else {
for (Entry<K, V> entry = table[index]; entry != null; entry = entry.nextEntry) {
if (entry.hashCode == hashCode && (entry.key == key || key.equals(entry.key))) {
entry.value = value;
return;
}
}
Entry<K, V> entry2 = table[index];
Entry<K, V> entry3 = new Entry<K, V>(key, value, hashCode);
entry3.nextEntry = entry2;
table[index] = entry3;
}
}
/*获得值*/
public V get(K key) {
int hashCode = this.toHashCode(key);
int index = hashCode % CAPACTITY;
if (table[index] == null) {
return null;
} else {
for (Entry<K, V> entry = table[index]; entry != null; entry = entry.nextEntry) {
if (entry.hashCode == hashCode && (entry.key == key || key.equals(entry.key))) {
return entry.value;
}
}
return null;
}
}
/*删除*/
public void remove(K key){
int hashCode = this.toHashCode(key);
int index = hashCode % CAPACTITY;
if (table[index] == null) {
return ;
} else {
Entry<K, V> parent=null;
for (Entry<K, V> entry = table[index]; entry != null; entry = entry.nextEntry) {
if (entry.hashCode == hashCode && (entry.key == key || key.equals(entry.key))) {
if(parent!=null){
parent.nextEntry=entry.nextEntry;
entry=null;
return ;
}
}
parent=entry;
}
}
}
public static void main(String[] args) {
HashMap<String,String> map=new HashMap<String,String>();
map.put("1", "2");
map.put("1", "3");
map.put("3", "哈哈哈");
System.out.println(map.get("1"));
System.out.println(map.get("3"));
map.remove("1");
System.out.println(map.get("1"));
}
}
class Entry<K, V> {
K key;
V value;
int hashCode;
Entry<K, V> nextEntry;
public Entry(K key, V value, int hashCode) {
super();
this.key = key;
this.value = value;
this.hashCode = hashCode;
}
}
/* 字符串hash算法 */
class StringHash {
public static final int toHashCode(String str) {
/* 我用java自带的 */
return str.hashCode();
}
}