ALS矩阵分解推荐模型
其实通过模型来预测1个user对1个item的评分,思想类似线性回归做预测,大致以下
定义1个预测模型(数学公式),
然后肯定1个损失函数,
将已有数据作为训练集,
不断迭代来最小化损失函数的值,
终究肯定参数,把参数套到预测模型中做预测。
矩阵分解的预测模型是:
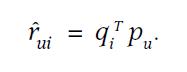
损失函数是:
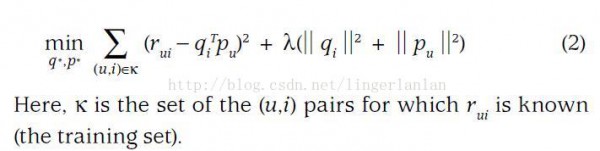
我们就是要最小化损失函数,从而求得参数q和p。
矩阵分解模型的物理意义
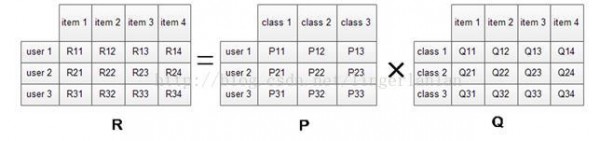
我们希望学习到1个P代表user的特点,Q代表item的特点。特点的每个维度代表1个隐性因子,比如对电影来讲,这些隐性因子多是导演,演员等。固然,这些隐性因子是机器学习到的,具体是甚么含义我们不肯定。
学习到P和Q以后,我们就能够直接P乘以Q就能够预测所有user对item的评分了。
讲完矩阵分解推荐模型,下面到als了(全称Alternatingleast squares)。其实als就是上面损失函数最小化的1个求解方法,固然还有其他方法比如SGD等。
als论文中的损失函数是(跟上面那个略微有点不同)
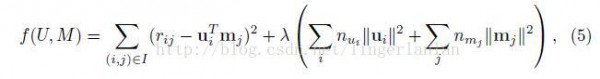
每次迭代,
固定M,逐一更新每一个user的特点u(对u求偏导,令偏导为0求解)。
固定U,逐一更新每一个item的特点m(对m求偏导,令偏导为0求解)。
论文中是这样推导的
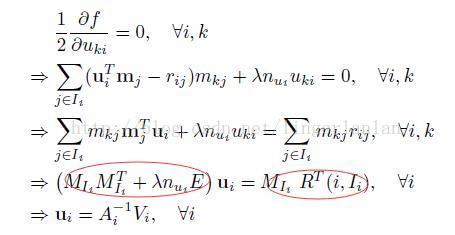
这是每次迭代求u的公式。求m的类似。
为了更清晰的理解,这里结合spark的als代码讲授。
spark源码中实现als有3个版本,1个是LocalALS.scala(没有用spark),1个是SparkALS.scala(用了spark做并行优化),1个是mllib中的ALS。
本来LocalALS.scala和SparkALS.scala这个两个实现是官方为了开发者学习使用spark展现的,
mllib中的ALS可以用于实际的推荐。
但是mllib中的ALS做了很多优化,不合适初学者研究来理解als算法。
因此,下面我拿LocalALS.scala和SparkALS.scala来说解als算法。
LocalALS.scala
// Iteratively update movies then users
for (iter <- 1 to ITERATIONS) {
println(s"Iteration $iter:")
ms = (0 until M).map(i => updateMovie(i, ms(i), us, R)).toArray //固定用户,逐一更新所有电影的特点
us = (0 until U).map(j => updateUser(j, us(j), ms, R)).toArray //固定电影,逐一更新所有用户的特点
println("RMSE = " + rmse(R, ms, us))
println()
}
//更新第j个user的特点向量
def updateUser(j: Int, u: RealVector, ms: Array[RealVector], R: RealMatrix) : RealVector = {
var XtX: RealMatrix = new Array2DRowRealMatrix(F, F) //F是隐性因子的数量
var Xty: RealVector = new ArrayRealVector(F)
// For each movie that the user rated 遍历该user评分过的movie.明显,这里默许该用户评分过所有电影,所以是0-M.实际利用求解,只需要遍历该用户评分过的电影.
for (i <- 0 until M) {
val m = ms(i)
// Add m * m^t to XtX 外积后 累加到XtX
XtX = XtX.add(m.outerProduct(m)) //向量与向量的外积:1个当作列向量,1个当作行向量,做矩阵乘法,结果是1个矩阵
// Add m * rating to Xty
Xty = Xty.add(m.mapMultiply(R.getEntry(i, j)))
}
// Add regularization coefficients to diagonal terms
for (d <- 0 until F) {
XtX.addToEntry(d, d, LAMBDA * M)
}
// Solve it with Cholesky 实际上是解1个A*x=b的方程
new CholeskyDecomposition(XtX).getSolver.solve(Xty)
}
再结合论文中的公式
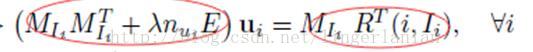
其实代码中的XtX就是公式中左侧红圈的部份,Xty就是右侧红圈的部份。
同理,更新每一个电影的特点m类似,这里不再重复。
SparkALS.scala
for (iter <- 1 to ITERATIONS) {
println(s"Iteration $iter:")
ms = sc.parallelize(0 until M, slices)
.map(i => update(i, msb.value(i), usb.value, Rc.value))
.collect()
msb = sc.broadcast(ms) // Re-broadcast ms because it was updated
us = sc.parallelize(0 until U, slices)
.map(i => update(i, usb.value(i), msb.value, Rc.value.transpose()))
.collect()
usb = sc.broadcast(us) // Re-broadcast us because it was updated
println("RMSE = " + rmse(R, ms, us))
println()
}
SparkALS版本相对LocalALS的亮点时,做了并行优化。LocalALS中,每一个user的特点是串行更新的。而SparkALS中,是并行更新的。
参考资料:
《Large-scale Parallel Collaborative Filtering for the Netflix Prize》(als-wr原论文)
《Matrix Factorization Techniques for Recommender Systems》(矩阵分解模型的好材料)
https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/LocalALS.scala
https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/SparkALS.scala
本文作者:linger
本文链接:http://blog.csdn.net/lingerlanlan/article/details/44085913