[置顶] 用机器学习来帮助吃货的你找最合适的聚点(Python描述)
Python 2.7
Pycharm 5.0.3
Geopy 1.11
图形展现 地图无忧-网页版
你可能需要知道
1.机器学习之K-means算法(Python描写)基础
2.经纬度地址转换的方法集合(Python描写)
3.想要知道怎样实现的可能还要python等相干知识
4.看官随便
前言
这次利害了,我爬出了哈尔滨市TOP285家好吃的店,包括烧烤的TOP,饺子的TOP,酱骨的TOP等等等等,在地图上显示,计划热门,再用聚类算法计算下能不能找出吃货最好的住宿点,能够距离吃的各个地方行程最近,吃货们,准备好了吗?
目的
可视化美食热门,计划各类美食聚集点,计划行程。
准备食材
首先,我不对这次排行的可信度负责,我只是直接百度的top餐厅,里面的水份大家自己权衡,甩锅给哈尔滨美食最新榜出炉,史上最强300家美食满足你各种挑剔!
大概是这样的
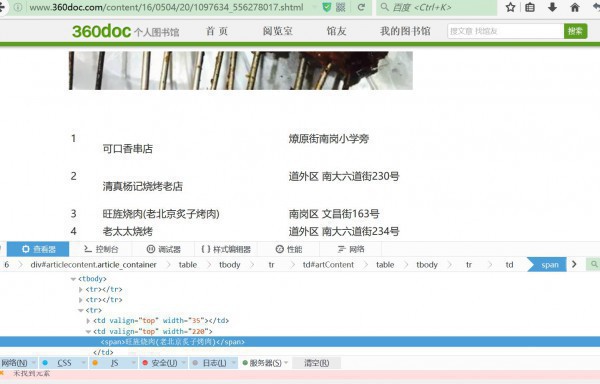
怎样爬我就不重复演示了,这里可以了解动态和静态爬的各种方法可以参考这里,有静态和动态的例子,这次我用静态爬发现被拦截了,mdzz,然后我就直接上selenium+Firefox(这里有1堆用Selenium的不累述了),至于为何不上PhantomJS,我这里说下,有时候PhantomJS爬的内容没有Firefox全,也许有人跳出来讲,你个sb,他两是1样的啊,而且PhantomJS更加省内存,呵呵,你自己去试试就知道了,我不止1次在爬动态的时候PhantomJS遇到问题而Firefox没有问题的(比如这个伪解决Selenium中调用PhantomJS没法摹拟点击(click)操作 ,连xpath都1样,就换了个无头,就不行了,我也有看到Stack Overflow上遇到一样问题的,多是我手法不够吧,也许是我真的理解错了,到时候我自来认错。
清洗食材
刚爬下来的数据肯定不能直接用的,又是空格又是序列的,处理的方法很多,可以用正则,sub换空格,然后splite切割,组成列表再取,洗的方法很多,具体看数据是怎样样的,洗完后放进冰箱,啊不是,放进txt或保存为csv,xls都可以的呢~

注意点
有些数据,大概34个,我清洗完以后发现有毛病,比如洗出个空格,额。。。。我尝试用try,except检测毛病,查看原始数据,发现源链接中的js写的不标准酿成的,哎,手动改好,再清洗1遍,不要刻意为了这1两个数据重写清洗算法,不就是sb了想着全自动1步成型,我咋不上天啊。。。
食材腌制-定位经纬度
这个我在上1篇文章中详细写了如何从1个地址转换得到相应的经纬度,可以查看经纬度地址转换的方法集合(Python描写)这里不再赘述,得到的数据格式有两种以下所示
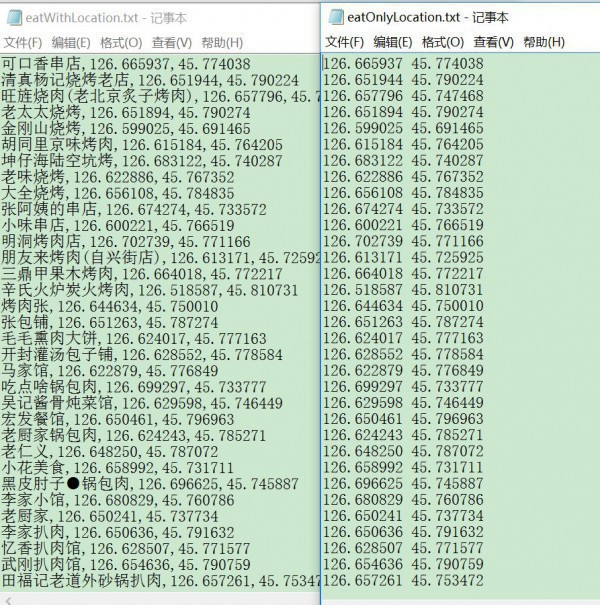
左1为地址+经纬度,逗号隔开,右1为经纬度,空格隔开,为何要生成两个格式?由于我喜欢啊,哈哈哈
食材保存–转化CSV
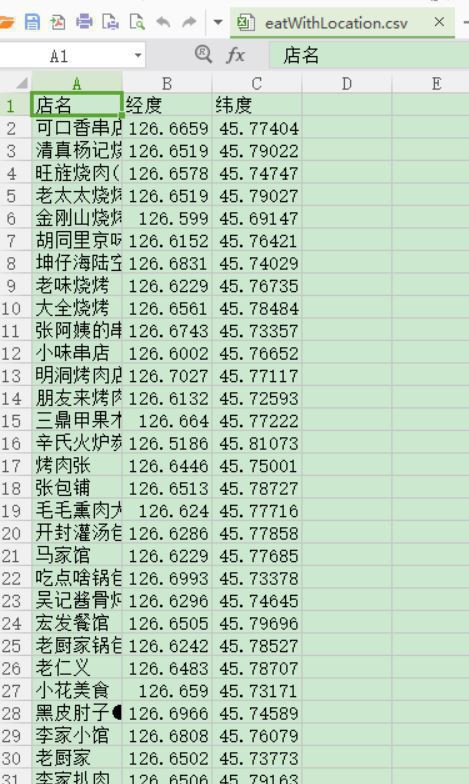
直接右键另存为,然后保存格式为.csv便可,有人说,为何不用csv的写入方法啊,由于我懒啊,我懒得重新构造字典了,这里甩上1段可以写入中文的csv格式。
import csv
import codecs
csvfile = file('csv_test.csv', 'wb')
csvfile.write(codecs.BOM_UTF8)
writer = csv.writer(csvfile)
writer.writerow(['姓名', '年龄', '电话'])
data = [
('%s', '25', '1234567'),
('С李', '18', '789456')
]
csvfile.close()弄完以后大概是这样的就能够下锅了
烹饪食材–聚类处理
我们要用的数据集是空格隔开的,至于为何空格隔开的经纬度数据,由于我之前写好的bikmeans里面输入项就是就是酱紫的,空格用正则比较好处理,用个list装下Obj.[0],[1]立马出来值了,至于Kmeans是啥,怎样用,请看机器学习之K-means算法(Python描写)基础,这里处理完后,我随机设置了5,10,15,204种聚类点,视察各种效果。代码我在附录放上,参考的可以直接取附录找。聚类处理以后照旧保存如上1步的1张图情势,以后就能够开始可视化了!
佳肴摆上桌–数据可视化
枯燥的数据让人很难受,根本分析不出甚么来,而且看着枯燥,这里我用了地图无忧这个网页版,虽然只有7天免费期,哎,辛辛苦苦画的图以后不能用了,(如果有谁知道还有类似的批量经纬度点转化图的软件请告知我1下)真蛋疼,这里快给大家分享看看吃货的地图,不看就没了!
具体的操作,直接看教程很简单的,我就是建图层,然后图层上批量放入经纬度,它就可以转化成地图上的点,很好玩,看个动图,这是我把点放上的效果。
享用佳肴–分析数据
- 先看下各种散布把,这个是热力图
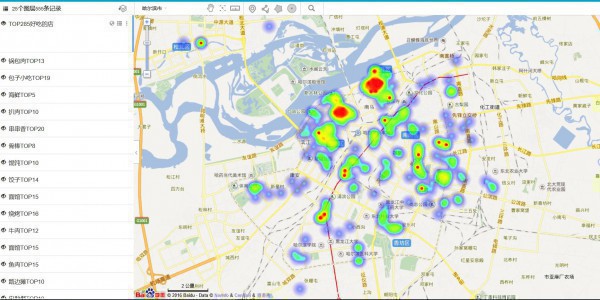
- 这个是点阵图
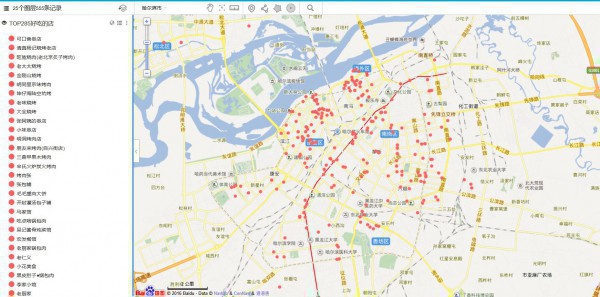
- 把聚类的点加上,选了聚类点为15个
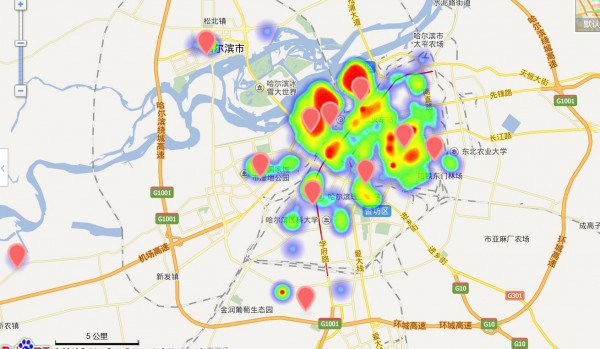
有些点不错,但是有些点太扯了把,貌似不是kmeans的主旨的,他是为了找距离各热门最近的平衡点啊,是聚类点啊,但是有几个点明显不是了,查看缘由。
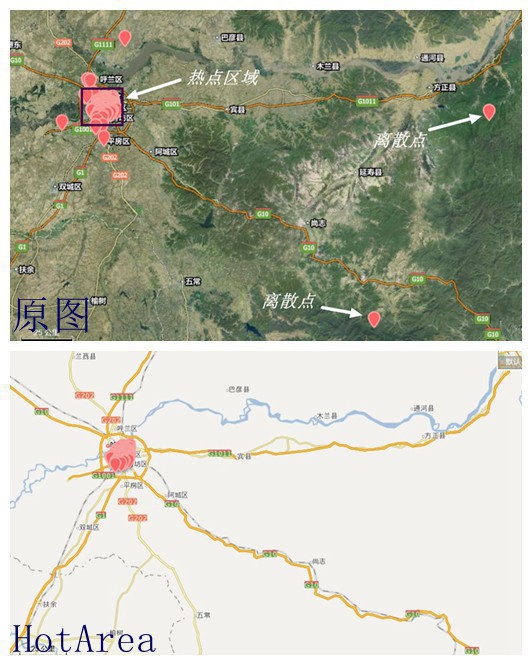
问题所在:可以看出来,上面的点散布缘由由于这些离散点的存在,我看了最远的点,亚布力滑雪场,的确有家店不错,额,可是我不斟酌,我要是在市区玩,我还想去那末远的地方?明显不公道,所以我需要的是真的热门区域,也就是第2幅的那样,所以又要重新洗1下数据了,把离散点也就是噪声去掉!
烧糊了–重新来
虽然整体上来讲,这个算法没错,但是如果对具体问题,比如说,我就想知道哈尔滨市内有甚么比较好吃的,我懒得动,不会跑到江北或更远的地方去吃,而且交通不方便,所以就要对经纬度集合进行切割,我找了适合返回,规定为经度范围126.56571~126.706807,纬度返回45.706283~45.802307,主程序中添加LockHotArea子函数,进行再1次过滤便可。
def LockHotArea(location):
HotArea = []
for i in location:
i = re.sub("\n",",",i)
i = re.split(",",i)
if (i[1]>"126.56571" and i[1]<"126.706807") and (i[2]>"45.706283" and i[2]<"45.802307"):
HotArea.append(i)
else:
print "far away from hotArea",i
return HotArea以后步骤重回前面的,最后的效果就是这样的
回锅肉–再分析数据
这回应当没有问题了,所以开始分析图吧
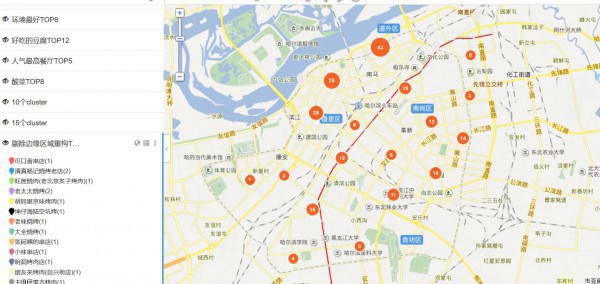
- 这里上20个聚类点的情况

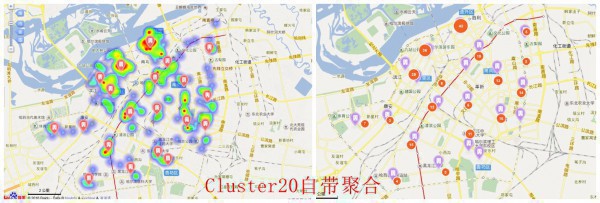
- 可以看出,聚类点的散布基本都在热门区域,说明比较符合情况,但是K的值其实不很能肯定,需要屡次实验k值
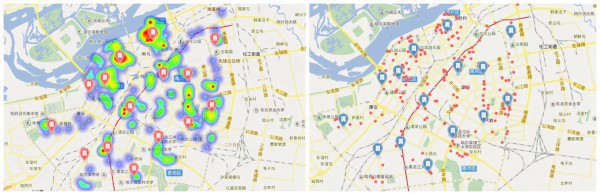
- cluster15,这些点就有点为难了。能说明甚么?多是住宿的最好点把,由于离各个好吃的距离是比较近的,这本来就是kmeans的核心。
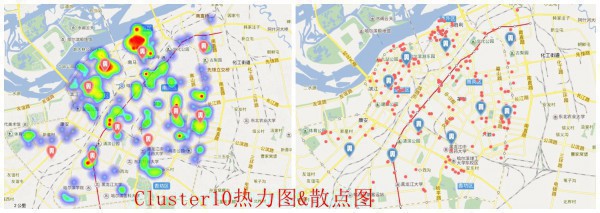
- cluster10的时候,聚类点就开始有点夸大了,虽然说很多仍在热力散布上,但是,有1些明显不在热力辐射返回内,但对能吃遍各个周围美食的人来讲,依然值得参考(这里不触及代步工具)
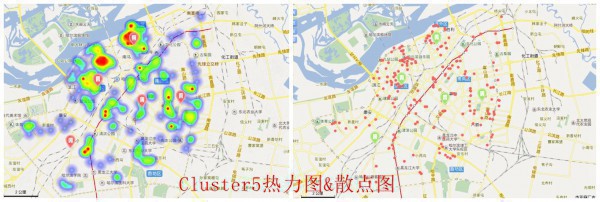
- cluster5的时候,只能算是保全大局式的选择离热门最近的点了,好坏需要自己判断
回锅肉上的1颗花椒–单点分析
这里我把24个TOP数据都摆上了图层,可以清晰的看出这些好吃的都散布在哪,这里放上几张示范图,具体自己想看的,可以自己吃货的地图自己定位
以包子TOP为例
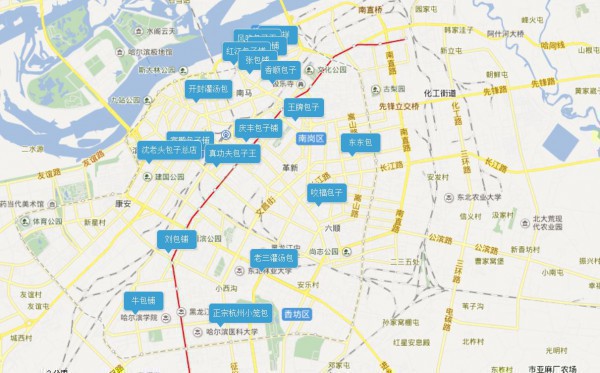
- 把包子的经纬度单独拿出来做聚类,分析出,喜欢吃包子的人住在哪才能更方便的吃上包子!

- 从上面的聚类点也能够看出,道外区是最多包子铺的,张包铺我也去吃过,排骨包里面真的有排骨!差点没把牙磕坏了,,,,跑题了,距离更多包子铺最近的点已给出,和辐射区范围接近,这里更合适做中转站,由于去各个包子铺都是最近的!
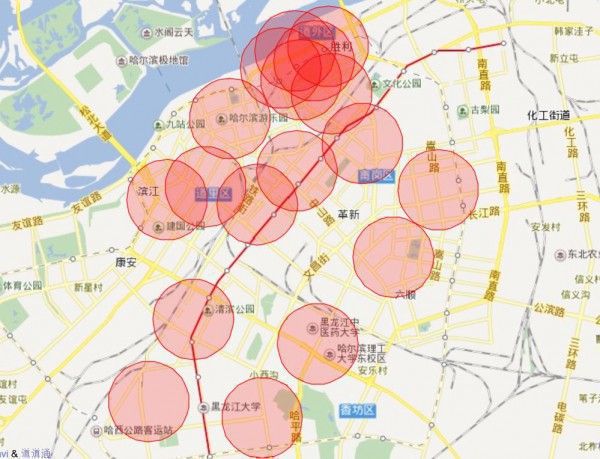
- 可以从图象自带缓冲区看堆叠部份,看包子热门
所以综上所述,喜欢吃包子的吃货,可以选择以上的点当作中转点或住宿点,到哪一个包子铺都是比较近的,但是!!!谁会1天3餐加夜消都吃包子??开个玩笑哈
更多组合
喜欢吃甚么,任君挑选,比如说,你又喜欢吃饺子又喜欢串串香,没问题,看看他们都在哪。聚类我没做,懒。和做包子聚类点类似,先把饺子的经纬度和串串香经纬度挑出来,再进行聚类便可

- 再比如包子和扒肉你都喜欢,那末看看重合区,不愧是老道外,真的是美食天堂啊!
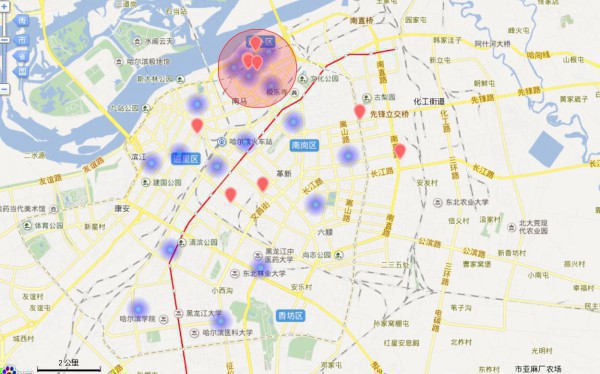
- 人气最高&口味最好~这个,额,我1家都没去过。。。。不做分析。。。
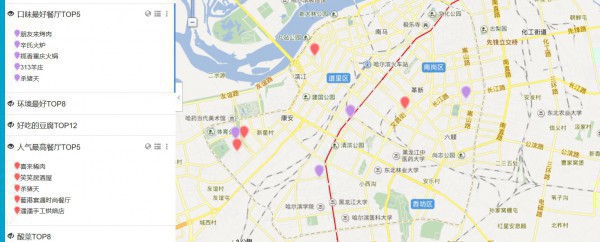
- 固然,你还有不可兼得的烧烤&酸菜,哭
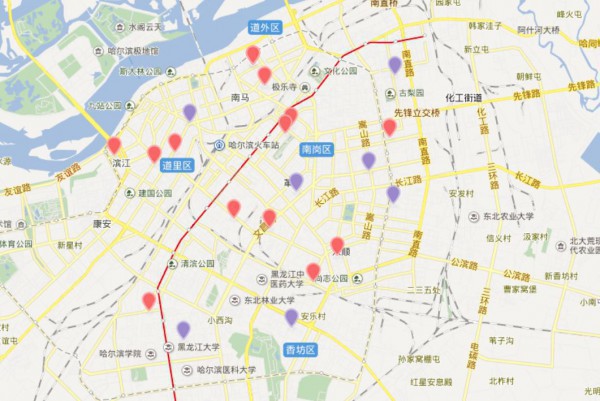
图就到这,更多美食大家自己去发现,点开图层就能够了~
Pay Atterntion
1.再进行对热门区域的切割的时候,需要比较阈值,出现了毛病,测试发现原来类型毛病,比较毛病,以下演示。
str1 = "250"
str2 = 250
print str1 > "300" # False
print str1 > 300 # True
print str2 > "100" # False
print str2 > 100 # True2.调用API经度误差的问题,具体演示这里,误差我看了1下。能调用的API精度误差大概百米多,没办法,能免费调用的API大家都懂的。
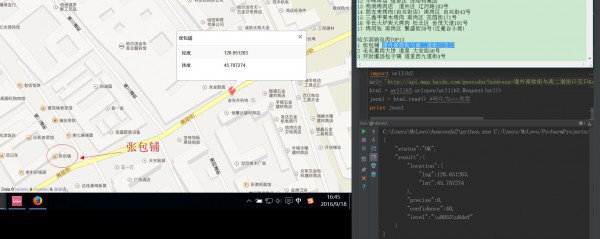
固然,很多都是比较准确的,比如这些。
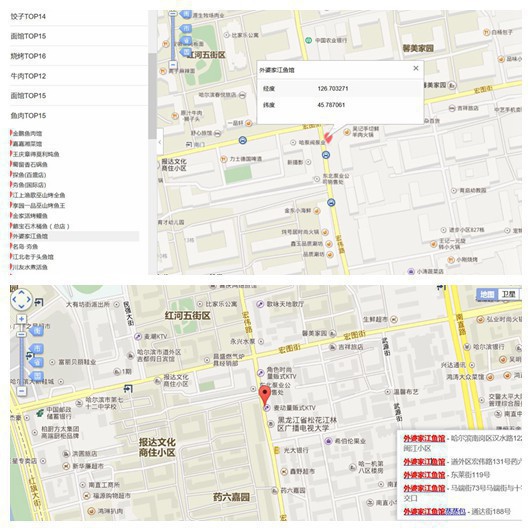
总结
终究住哪,这不是我能决定的,主要还是靠交通,住宿环境和个人心情,推荐住在地铁附近,吃货可以选择在中央大街附近,最繁华,也里老道外很近,好吃的很多~诶,等等,我不是在做学术研究么,怎样成旅游节目了。。

附录–代码
这是核心程序,调用的API_get子程序太长了,请参考经纬度地址转换的方法集合(Python描写)或在这里进行下载使用源代码集合
# -*- coding: utf⑻ -*-
# Author:哈士奇说喵
import re
import API_get
#写入txt操作子函数
def write2txt(file,txtname):
f = open(txtname,'a')
f.write(file)
f.write("\n")
f.close()
# please use this with try except/finall f.close()
f = open("C:\\Users\\MrLevo\\PycharmProjects\\test\\KmeansEat.txt","r")
lines = f.readlines()
eatlocation = []
i = 0
# 清洗+转换经纬度
for line in lines:
line = re.sub("\n"," ",line)
line = re.sub(" +"," ",line)
line = re.split(" ",line)
try:
line_shopname = line[1].strip()
try:
line = line[2]+line[3]
#print line
line = "哈尔滨市"+line
line =line.strip()
try:
lat_lng,lng_latWithCommon = API_get.getLocation_xml(line)
shopWithLocation= "%s,%s"%(line_shopname,lng_latWithCommon)
print shopWithLocation
eatlocation.append(shopWithLocation)
#write2txt(lat_lng,"eatOnlyLocation.txt")
except:
print "failed %s"%line
i +=1
except:
line = line[2]
line = "哈尔滨市"+line
line =line.strip()
try:
lat_lng,lng_latWithCommon = API_get.getLocation_xml(line)
shopWithLocation = "%s,%s"%(line_shopname,lng_latWithCommon)
print shopWithLocation
eatlocation.append(shopWithLocation)
#write2txt(lat_lng,"eatOnlyLocation.txt")
except:
print "failed %s"%line
i +=1
except:
pass
print "failed!%d"%i
# 清洗热门
def LockHotArea(location):
HotArea = []
for i in location:
i = re.sub("\n",",",i)
i = re.split(",",i)
if (i[1]>"126.56571" and i[1]<"126.706807") and (i[2]>"45.706283" and i[2]<"45.802307"):
HotArea.append(i)
else:
print "far away from hotArea",i
return HotArea
HotArea = LockHotArea(eatlocation)
#写入数据
for i in HotArea:
rebuild = "%s,%s,%s"%(i[0],i[1],i[2])
write2txt(rebuild,"HotAreaWithCommon.txt")本文已结束,以下是同类型样本,我测试着玩的
跑题项
本来想着分析1下GDP TOP
100的城市之间的关系,看看能不能用聚类的方法,得出甚么成心义的答案,可是,我觉得并没有甚么啊,难道说,找个开会的地方,能够离各大经济强市距离最近的?貌似其余没甚么用啊–不行,我不甘心白做数据和图!
首先来个动图!分别是10,20,40个聚类点构成的热力辐射图
数据来源
上1篇中经纬度地址转换方法集合中已将GDP TOP100的城市爬下来并且已转换好数据保存好了,直接拿来批量放在地图上便可
试着分析
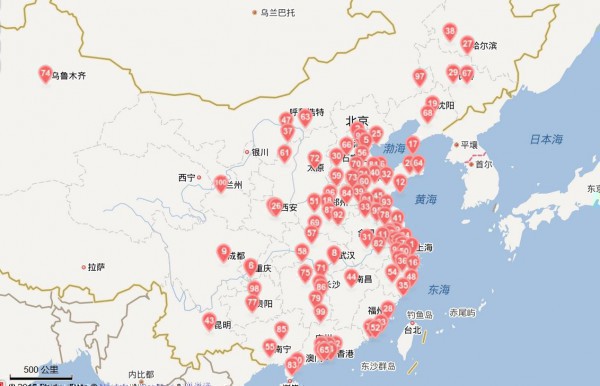
GDP排名城市显示
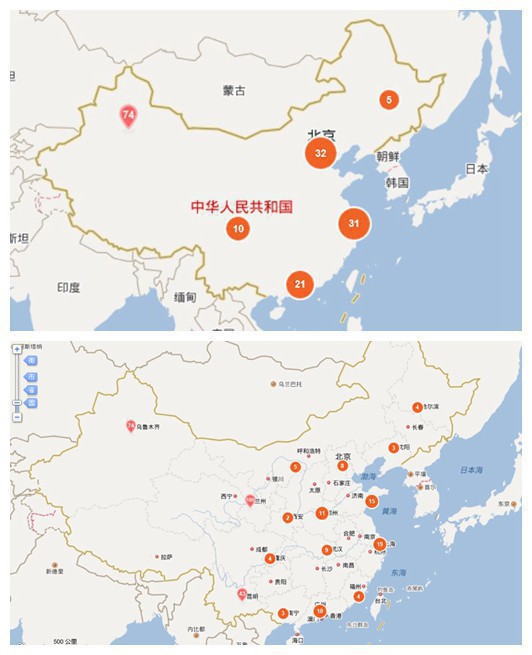
其中乌鲁木齐市排名,由于是单点,,,,其余的都是城市聚集个数
热力图显示
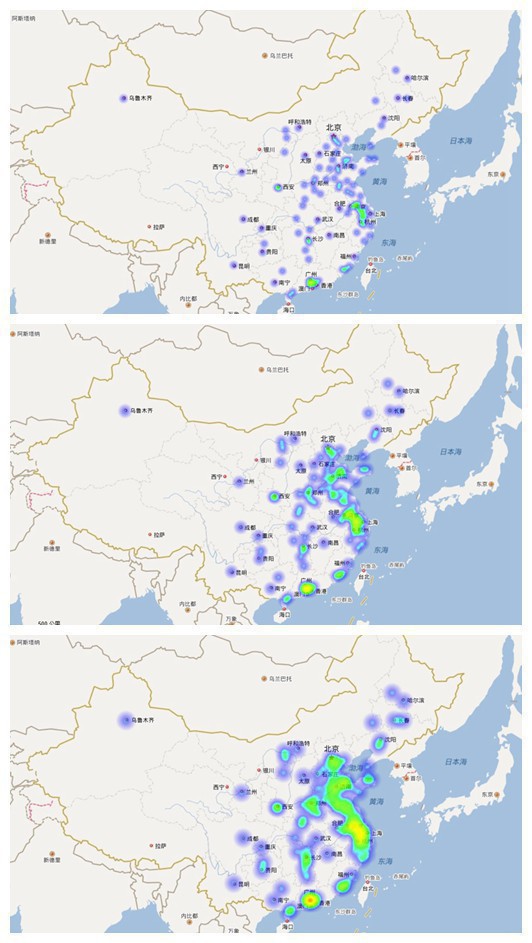
经济盲我就不斯以揣测了,沿海地区百花齐放,内陆地区单点开花??

聚类分析

蓝色为聚类点,红色为TOP10强市,黄色是剩下的TOP90城市。请告知我!能看出啥,能看出啥?????
(严肃脸)各大经济城市召开峰会,谁也不服谁,到哪开会呢?好的,就找离各个经济强市都近的中间点把,对大家还公平,还可以拉动下开会城市GDP。哈哈哈

最后
至于各个省的分别占都少,我没有在做下去,觉得意义不是很大,当作练手了。
致谢
@MrLevo520–机器学习之K-means算法(Python描写)基础
@MrLevo520–经纬度地址转换的方法集合(Python描写)
哈尔滨美食最新榜出炉,史上最强300家美食满足你各种挑剔!
伪解决Selenium中调用PhantomJS没法摹拟点击(click)操作