一、Hadoop 2.x 分布式安装部署
1、Hadoop 2.x 散布式安装部署
1.散布式部署hadoop 2.x
1.1克隆虚拟机并完成相干配置
1.1.1克隆虚拟机
点击原有虚拟机–>管理–>克隆–>下1步–>创建完成克隆–>写入名称hadoop-senior02–>选择目录
1.1.2配置修改
1)启动克隆虚拟机(内存配置:01:2G;02:1.5G;03:1.5G)
2)修改主机名:改两处
3)修改网卡名称
编辑 /etc/udev/rules.d/70-persistent-net.rules
—>注释掉包括eth0的行
—>把包括eth1行中的eth1改成eth0

编辑 /etc/sysconfig/network-script/ifcfg-eth0
—>将mac地址改成虚拟机设置的地址

5)配置完后重启
6)设置固定IP

7)将3台机器都连接到crt
1.2对集群中的虚拟机进行基本配置准备工作
1)首先将/tmp目录下的所有东东都删掉
$cd /tmp
$sudo rm -rf ./*
2)将hadoop⑵.5.0,maven,m2所有删除
$cd /opt/modules/
3)将所有机器的主机名和IP映照好
编辑/opt/hosts
将所有机器添加每台机器的映照,即在每台虚拟机上打开该文件,并以下添加:

在windows中Hosts文件也一样配置映照

如此在任1机器上都可以连接集群中的其他有机器。
4)在所有机器的opt目录下添加1个目录/app/并修改归属,所有集群都在这下面做(集群的安装目录必须统1!)
$sudo mkdir /opt/app
$sudo chown -R beifeng:beifeng /opt/app/
5)将hadoop⑵.5.0解压到app目录下(将1台机器配好,然后发送给其他机器)
$tar -zxf /opt/softwares/hadoop⑵.5.0.tar.gz -C /opt/app/
1.3公道计划hadoop服务组件部署
散布式架构都采取主从架构,若为伪散布式则主从都在1台机器,若散布式则主节点在1台机器,从节点在多台机器。1般把datanode和nodermanager放在1台机器上,前者使用电脑磁盘空间去存储数据,后者使用内存与CPU去计算分析数据。
若使用3台虚拟机则可配置以下
| 3台 | hadoop-senior | hadoop-senior02 | hadoop-senior03 |
|---|---|---|---|
| 内存 | 2G | 1.5G | 1.5G |
| CPU | 1核 | 1核 | 1核 |
| 硬盘 | 20G | 20G | 20G |
| 服务组件 | namenode | ||
| resourcemanager | |||
| datanode | datanode | datanode | |
| nodemanager | nodemanager | nodemanager | |
| MRHistoryserver | secondarynamenode |
若使用2台虚拟机则可配置以下(本次练习只使用两台机器)
| 2台 | hadoop-senior | hadoop-senior02 |
|---|---|---|
| 内存 | 2G | 1.5G |
| CPU | 1核 | 1核 |
| 硬盘 | 20G | 20G |
| 服务组件 | resoucemanager | |
| namenode | ||
| datanode | datanode | |
| nodemanager | nodemanager | |
| secondarynamenode | MRHistoryserver |
1.4以【hadoop 2.x伪散布式部署】为模板,配置各个服务组件部属节点
1.4.1配置${JAVA_HOME}
打开hadoop-evn.sh,mapred-env,yarn-env.sh
配置jdk的目录给JAVA_HOME

1.4.2配置hdfs
创建tmp目录:
$mkdir -p /opt/app/hadoop2.5.0/data/tmp
打开core-site.xml,添加配置以下:

打开slaves,配置以下

打开hdfs-site.xml
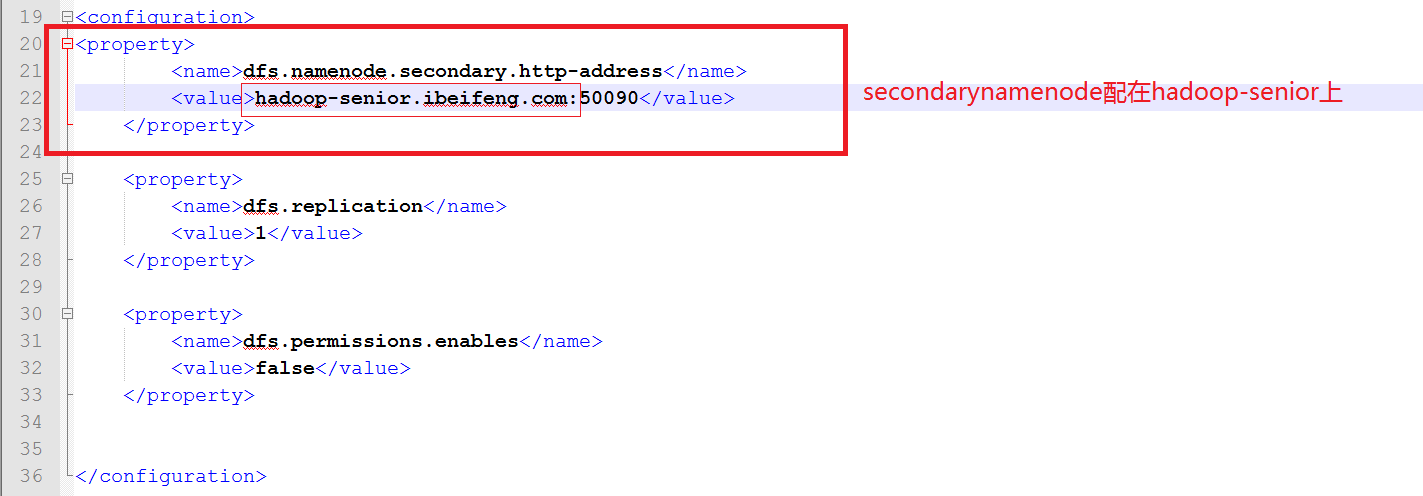
1.4.3配置yarn
打开yarn-site.xml, 配置以下:
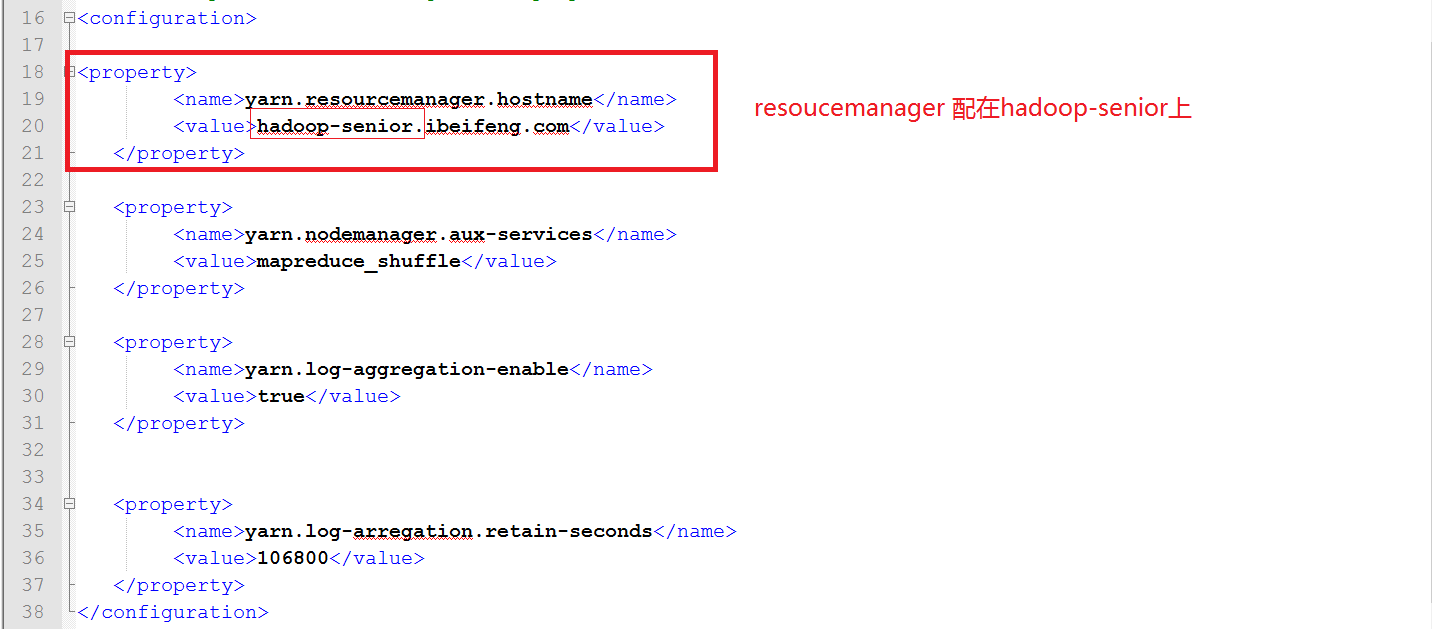
1.4.4配置historyserver
打开mapred.site.xml,配置以下:
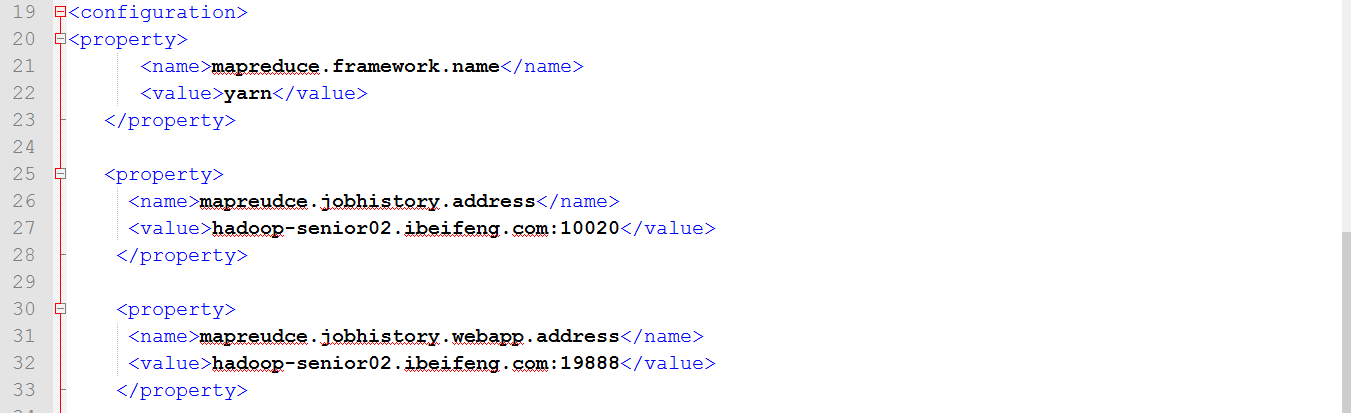
1.5分发hadoop到个机器,并启动hdfs,yarn
1.5.1分发
$scp -r hadoop-2.5.0/ beifeng@hadoop-senior02.ibeifeng.com:/opt/app/1.5.2启动HDFS,YARN
1)先格式化hdfs
2)启动 senior02的namenode,两台datanode
3)启动senior的resourcemanager,两台nodemanager
4)启动senior02的Jobserver
5)启动senior的secondarynamenode


WEB UI查看datanode已生成了2个
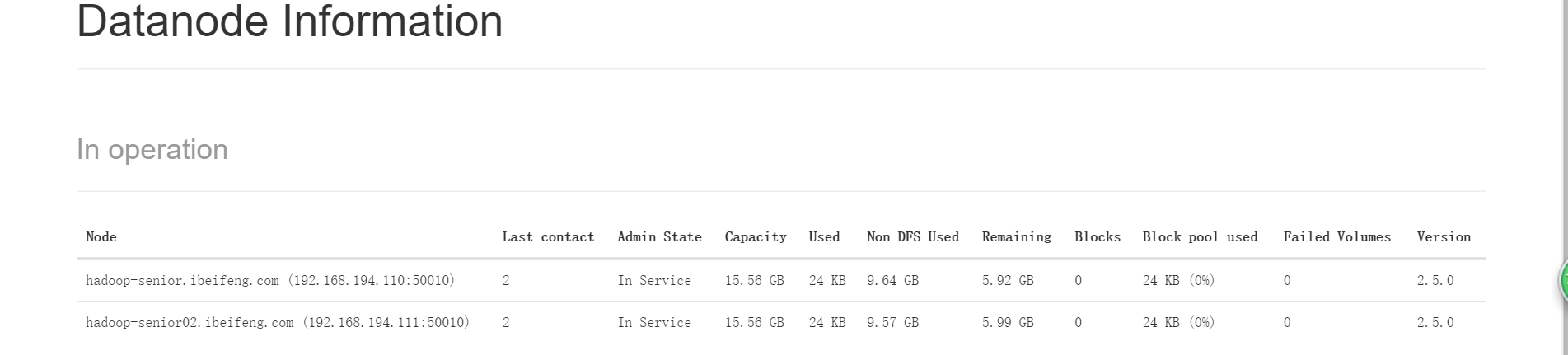
WEB UI查看 nodemanager也有两个
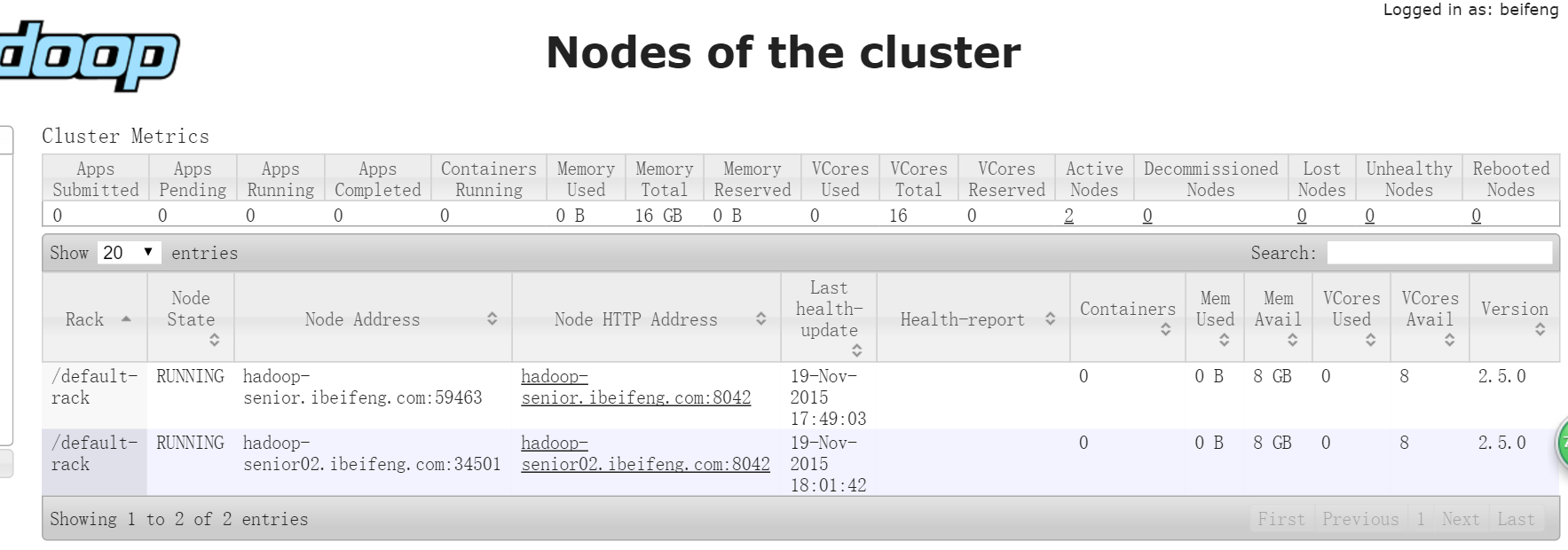
1.6测试
1.6.1上传文件
新建目录
$bin/hdfs dfs -mkdir -p tmp/conf上传文件
$bin/hdfs dfs -put etc/hadoop/*-site.xml tmp/conf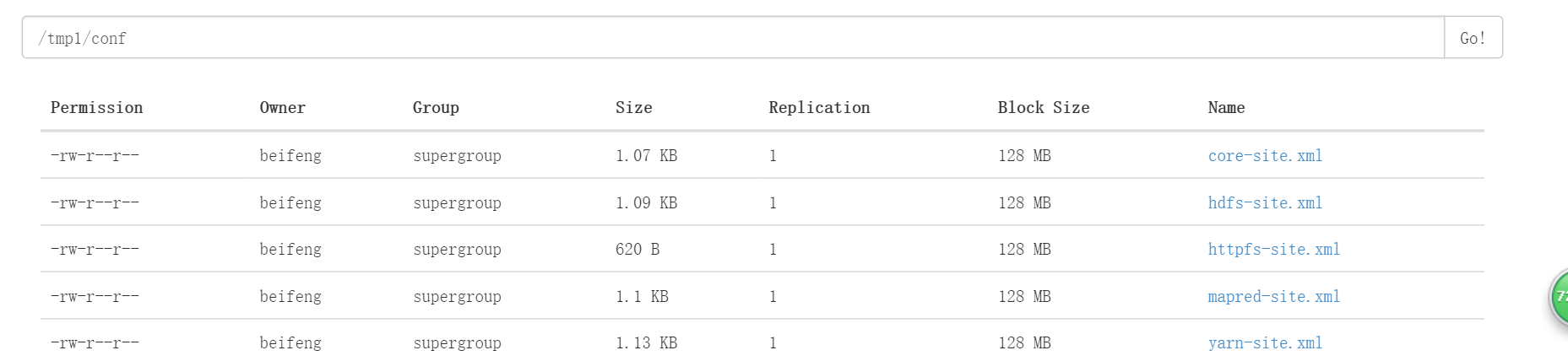
读取文件
$bin/hdfs dfs -text tmp/conf/core-site.xml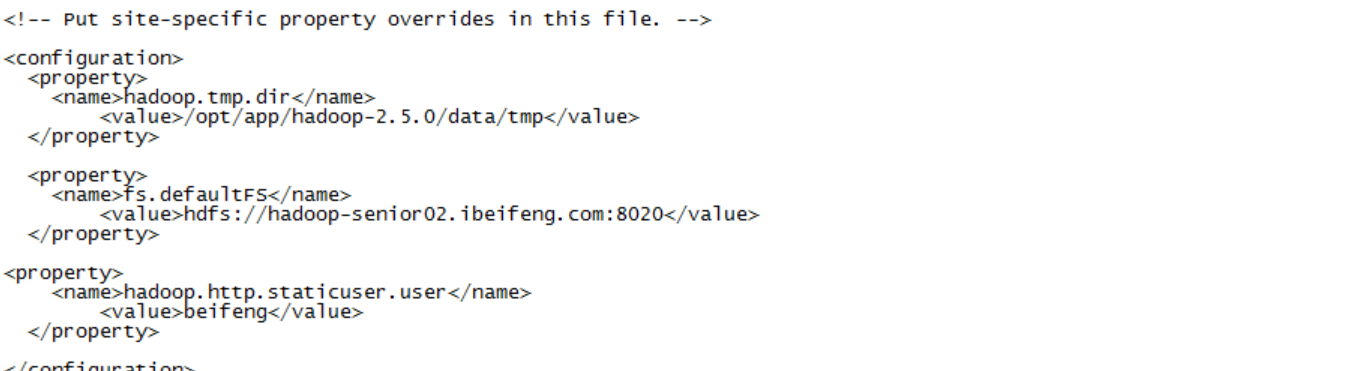
1.6.2 wordcount程序测试
1)新建目录
$bin/hdfs dfs -mkdir -p mapreduce/wordcount/input2)上传文件到目录
bin/hdfs dfs -put /opt/datas/wc.input mapreduce/wordcount/input
3)运行wordcount程序
$bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount mapreduce/wordcount/input mapreduce/wordcount/output
4)读取文件
$bin/hdfs dfs -text mapreduce/wordcount/output/par*
1.6.3基准测试(指南p315)
测试磁盘内存
1)
$bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar2)
$bin/yarn jar hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.5.0.jar1.7配置ssh无秘钥登入
现将原本的全删掉:
$cd .ssh/
$rm -rf ./*在主节点上分别配置nodemanager 和 resourcemanage两个主节点:
1)生成1对公钥与密钥
$ssh-keygen -t rsa2)拷贝公钥到各个机器上
$ssh-copy-id bigdata-senior.ibeifeng.com
$ssh-copy-id bigdata-senior02.ibeifeng.com3)shh链接
$ssh bigdata-senior.ibeifeng.com
$ssh hadoop-senior02.ibeifeng.com如图
1.8集群时间同步
集群时间同步
1.8.1 找1台机器作为时间服务器,所有机器与这台时间服务器进行同步时间
如在01机上:
1)查看时间服务器是不是安装:
sudo rmp -qa|grep ntp2)查看时间服务器运行状态
sudo service ntp status 3)开启时间服务器
sudo chkconfig ntpd start4)设置随机启动
sudo chkconfig ntpd on5)查看启动状态
sudo chkconfig --list|grep ntpd6)配置文件
sudo vi /etc/ntp.conf3处修改:
(1)删除下1行的注释,并修改网段(IP地址的前3串,后面为.0)
restrict 192.168.194.0 mask 255.255.255.0 nomodify notrap
(2)将时间服务器server注释掉
#server 0.centos.pool.ntp.org
#server 1.centos.pool.ntp.org
(3)去掉以下两行注释
server 127.127.1.0....
fudge 127.127.1.1.0.....
7)重启服务器
sudo service ntpd restart8)时间服务器与bios同步
$sudo vi /etc/sysconfig/ntpd添加内容:
SYNC_HWLOCK=yes
等待5分钟
1.8.2 配置所有机器与该机器同步
1)配置所有机器与这台hadoop-senior机器同步
sudo /usr/sbin/ntpdate hadoop-senior.ibeifeng.com2)写1个定时任务,每过1段时间与时间服务器进行同步时间
首先切换到root
设置每过10分钟更新1次同步
$sudo crontab -e加入:0⑸9/10* * * */user/sbin/ntpdate hadoop-senior.ibeifeng.com
3)设置时间
sudo date -s 2015-11-17
sudo date -s 17:54:00上一篇 [置顶] 打印1到最大的n位数
下一篇 Podfile文件详解