本文将介绍图的深度优先搜索,并实现基于深度优先搜索的拓扑排序(拓扑排序适用于有向无环图,下面详细介绍)。
1. 图的深度优先遍历要解决的问题
图的深度优先搜索与树的深度优先搜索类似,但是对图进行深度优先搜索要解决1个问题,那就是顶点的重复访问,假定图中存在1个环路A-B-C-A,那末对顶点A进行展开后得到B,对B进行展开后得到C,然后对C进行展开后得到A,然后A就被重复访问了。。。
这明显是不对的!我们需要用1个状态变量来记录1个顶点被访问和被展开的状态。在《算法导论》中,作者使用3种色彩来对此进行标记:WHITE——顶点还没被访问过,GRAY——顶点已被访问过但是其子结点还没被访问完,BLACK——顶点已被访问过而且其子结点已被访问完了。
2. 用栈实现图的深度优先遍历
在《算法导论》中,作者使用了递归来实现深度优先遍历。虽然递归写起来更加简洁而且容易理解,但是我其实不建议在实际工程中这样做,除非你的问题范围比较小。否则递归会让你的程序万劫不复。正如使用队列实现广度优先搜索1样(可以看到我的上1篇博客图的广度优先遍历),下面我将会使用栈来实现深度优先搜索。
下面用1个例子来讲明如何使用栈来实现深度优先遍历。假定有下面1个图。
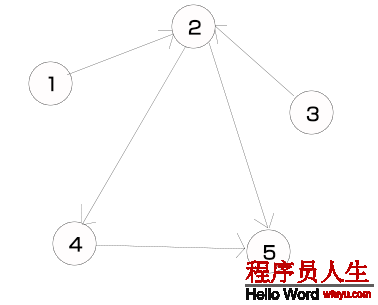
首先,我们初始化1个空栈,然后将所有顶点入栈,此时所有顶点都没有被访问过,因此所有顶点都置为白色,以下所示。
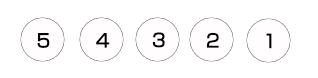
上述初始化完成以后,顶点5位于栈底,顶点1位于栈顶,然后我们就进入循环操作,首先出栈1个顶点,该顶点为顶点1,由于顶点1是白色的,即没有被访问过,因而就将顶点1置为灰色,并重新入栈(由于下面要记录结点的子结点被访问完的次序),然后展开顶点1的所有顶点,只有顶点2,由于顶点2是白色即未被访问过,因而将顶点2入栈,以下图所示。
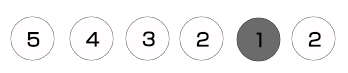
然后我们继续循环,出栈1个顶点,即顶点2,由于顶点2是白色的,因而将其置为灰色,并重新入栈,然后展开得到顶点4和顶点5,由于顶点4和顶点5均为白色,因而将它们都入栈。以下图所示。

然后还是继续循环,出栈1个顶点,即顶点5,由于顶点5是白色的,因而将其置为灰色,并重新入栈,然后展开顶点5,发现顶点5没有子结点,以下图所示。

然后继续循环,出栈顶点5,此时顶点5为灰色,说明顶点5的子结点已被访问完了,因而将顶点5置为黑色,并将其次序标记为1,说明他是第1个被展开完的结点,这1个记录将会被利用到拓扑排序中。此时栈的状态以下所示。
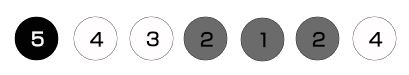
继续循环,出栈顶点4,由于是白色的,所以将顶点4置为灰色并重新入栈,然后展开顶点4得到顶点5,由于顶点5是黑色的,因而不将其入栈。接下来继续出栈顶点4,发现顶点4是灰色的,因而和前面1样,将顶点4置为黑色并将其次序记录为2。此时的栈以下图所示。

好了,后面的循环的工作也跟上述类似,顺次将顶点2、1出栈并置为黑色,直到顶点3展开发现没有白色的子结点,也将其置为黑色。然后再到了顶点4和顶点5,由于是黑色,直接出栈不作任何处理了。此时栈为空,遍历结束。
我们的程序需要的输入的图以邻接表的情势表示,下面给出图及顶点和邻接表的定义。
typedef enum VertexColor
{
Vertex_WHITE = 0, // 未被搜索到
Vertex_BLACK = 1, // 子结点都被搜索终了
Vertex_GRAY = 2 // 子结点正在被搜索
} VertexColor;
typedef struct GNode
{
int number; // 顶点编号
struct GNode *next;
} GNode;
typedef struct Vertex
{
int number;
int f;
VertexColor color; // 搜索进程标记搜索状态
struct Vertex *p;
} Vertex;
typedef struct Graph
{
GNode *LinkTable;
Vertex *vertex;
int VertexNum;
} Graph;
VertexColor是顶点的色彩枚举量定义。GNode是邻接表的元素定义,其记录了顶点的编号。邻接表本质上就是1个指针数组,其每一个元素都是指向1个链表的第1个元素的指针。Vertex是顶点的数据结构,其属性number为顶点编号,f是记录其被访问完的次序,color是状态标识色彩,p指向搜索完成后得到的深度优先遍历树中的顶点的先驱。Graph是图的数据结构定义,其包括了1个顶点数组,按编号升序排列,LinkTable是邻接表。
下面给出用栈实现的深度优先搜索的程序。
/**
* 深度优先搜索,要求输入图g的结点编号从1开始
*/
void searchByDepthFirst(Graph *g)
{
int VertexNum = g->VertexNum;
Stack *stack = initStack();
Vertex *vs = g->vertex;
GNode *linkTable = g->LinkTable;
int order = 0;
for (int i = 0; i < VertexNum; i++)
{
Vertex *v = vs + i;
v->color = Vertex_WHITE;
v->p = NULL;
push(&stack, v->number);
}
while (!isEmpty(stack))
{
int number = pop(&stack);
Vertex *u = vs + number - 1;
if (u->color == Vertex_WHITE)
{
// 开始搜索该结点的子结点
u->color = Vertex_GRAY;
push(&stack, number);
}
else if (u->color == Vertex_GRAY)
{
// 该结点的子结点已被搜索完了
u->color = Vertex_BLACK;
u->f = order++;
continue;
}
else
{
continue;
}
GNode *links = linkTable + number - 1;
links = links->next;
while (links != NULL)
{
// 展开子结点并入栈
Vertex *v = vs + links->number - 1;
if (v->color == Vertex_WHITE)
{
v->p = u;
push(&stack, links->number);
}
links = links->next;
}
}
}
程序先将所有顶点初始化为白色并入栈,然后开始循环。在循环中,每次出栈1个结点都要先对其色彩进行判断,如果是灰色,标记其被访问完成的次序并标为黑色,如果是黑色,不作任何处理,如果是白色,则置为灰色并重新入栈,然后展开其所有子结点并将白色的子结点入栈,并且记下这些白色顶点的先驱。当栈为空时,循环结束。
栈的操作可以参考其它资料,这里不做详述,下面给出1个简单实现。
typedef struct Stack {
int value;
struct Stack *pre;
} Stack;
上面是栈的结构定义。
Stack* initStack()
{
Stack *s = (Stack *)malloc(sizeof(Stack));
s->pre = NULL;
return s;
}
void push(Stack **s, int value)
{
Stack *n = (Stack *)malloc(sizeof(Stack));
n->pre = *s;
n->value = value;
*s = n;
}
int pop(Stack **s)
{
if ((*s)->pre == NULL)
{
return INT_MAX;
}
int value = (*s)->value;
Stack *pre = (*s)->pre;
free(*s);
*s = pre;
return value;
}
int isEmpty(Stack *s)
{
if (s->pre == NULL)
{
return 1;
}
return 0;
}
void destroyStack(Stack **s)
{
while (*s != NULL)
{
Stack *pre = (*s)->pre;
free(*s);
*s = pre;
}
}
上面是栈的方法,顺次是初始化1个空栈,入栈,出栈,判断是不是为空栈,烧毁栈。
下面给出1个利用上述深度优先遍历方法的例子代码和运行结果。
Graph graph;
graph.VertexNum = 5;
Vertex v[5];
Vertex v1; v1.number = 1; v1.p = NULL; v[0] = v1;
Vertex v2; v2.number = 2; v2.p = NULL; v[1] = v2;
Vertex v3; v3.number = 3; v3.p = NULL; v[2] = v3;
Vertex v4; v4.number = 4; v4.p = NULL; v[3] = v4;
Vertex v5; v5.number = 5; v5.p = NULL; v[4] = v5;
graph.vertex = v;
GNode nodes[5];
GNode n1; n1.number = 1;
GNode n2; n2.number = 2;
GNode n3; n3.number = 3;
GNode n4; n4.number = 4;
GNode n5; n5.number = 5;
GNode y; y.number = 5;
GNode e; e.number = 2;
GNode f; f.number = 5;
GNode g; g.number = 2;
GNode h; h.number = 4;
n1.next = &e; e.next = NULL;
n2.next = &h; h.next = &f; f.next = NULL;
n3.next = &g; g.next = NULL;
n4.next = &y; y.next = NULL;
n5.next = NULL;
nodes[0] = n1;
nodes[1] = n2;
nodes[2] = n3;
nodes[3] = n4;
nodes[4] = n5;
graph.LinkTable = nodes;
searchByDepthFirst(&graph);
printf("\n");
printPath(&graph, 2);
运行结果以下。
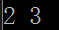
上述示例代码对本文前面给出的图进行深度优先遍历后,输出顶点2的先驱子树,得到上述结果,意思是顶点2的先驱顶点为3。
3. 图的拓扑排序
图的拓扑排序可以利用深度优先遍历来实现。
首先,说明1下甚么是拓扑排序。拓扑排序是指将图按前后顺序组织排列起来,前后顺序是指在排序结果中,前面的顶点多是有1条简单路径通向后面的顶点的,而后面的顶点是肯定没有1条简单路径通向前面的顶点的。拓扑排序适用于有向无环图。下面给出1个拓扑排序的例子。
还是这个图,这也是1个有向无环图,拓扑排序的结果最前面的顶点肯定是1个根顶点,即没有其它顶点指向他。这个图的拓扑排序结果是1、3、2、4、5,或1、3、2、5、4,等等,不存在指向关系的顶点间的顺序是不肯定的。我们可以将拓扑排序的图看成是1个日程表,顶点1代表洗脸,顶点3代表刷牙,顶点2代表吃早饭,顶点4代表穿裤子,顶点5代表穿衣服,因而拓扑排序本质就是根据事件应当产生的前后顺序组织起来。
图的深度优先遍历有1个特点,那就是,当1个顶点的子结点都被访问完了,该顶点才会结束访问,并开始向上回溯访问它的父结点的其它子结点。这意味着,1个顶点的结束访问时间与其子结点的结束访问时间存在前后关系,而这个顺序恰好与拓扑排序是相反的!简单地说,在深度优先遍历中,顶点A要结束访问的条件是其子结点B、C、D...都被访问完了,而在拓扑排序中,事件A完成以后其后面的事件B、C、D...才可以继续进行。这也就是上面的深度优先搜索为何要记录结点被访问完成的次序,由于这个次序倒过来就是拓扑排序的顺序!
下面给出基于图的深度优先搜索实现的拓扑排序的程序。
/**
* 有向无环图的拓扑排序
*/
void topologySort(Graph *g, int **order, int *n)
{
searchByDepthFirst(g);
*n = g->VertexNum;
*order = (int *)malloc(sizeof(int) * *n);
for (int i = 0; i < *n; i++)
{
(*order)[*n - 1 - g->vertex[i].f] = i + 1;
}
}
一样的,上述程序实现的拓扑排序要求的图的顶点编号也是从1开始。
其实拓扑排序还有另外一种实现方法,那就是从根顶点开始,删除所有根顶点及与之相连的边。此时就会产生新的根顶点,然后继续重复上述操作,知道所有顶点都被删除。
4. 总结
本文介绍了如何使用栈来实现图的深度优先搜索,并基于图的深度优先搜索实现了拓扑排序。其时间复杂度均为O(n)。完全程序可以参考我的github项目数据结构与算法
这个项目里面有本博客介绍过的和没有介绍的和将要介绍的《算法导论》中部份主要的数据结构和算法的C实现,有兴趣的可以fork或star1下哦~ 由于本人还在研究《算法导论》,所以这个项目还会延续更新哦~ 大家1起好好学习~