R语言的数据结构
R具有许多用于存储数据的对象类型,包括标量、向量、矩阵、数组、数据框和列表
1 标量
标量是只含1个元素的向量,例如a<- 3、b <- "US"和c <- TRUE。它们用于保存常量
2 向量
R中的向量可以理解为1维的数组,每一个元素的mode必须相同.
函数c,是组合函数,可以用创建数组,如
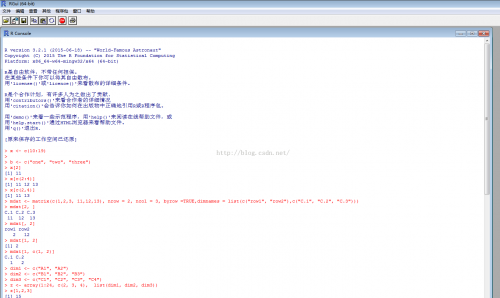
x <- c(10:19)
b <- c("one", "two", "three")
x[2] 访问数组中第2个元素。这里没有下标,从 1 开始计算距离
x[c(2:4)] 访问数组中第2到4个元素
x[c(2,4)] 访问数组中第2个和第4个元素
3 矩阵
可以理解为2维数组,每个元素必须要有相同的mode,使用matrix进行创建,matrix的情势为:
matrix(data = NA, nrow = 1, ncol = 1, byrow = FALSE,
dimnames = NULL)该函数中,vector中为矩阵的元素,nrow表示行数,ncol表示列数,byrow为1个布尔向量表示是不是依照行动主进行填充,默许依照列为主,dimnames为可选的制定行和列的名称。
mdat <- matrix(c(1,2,3, 11,12,13), nrow = 2, ncol = 3, byrow =TRUE,dimnames = list(c("row1", "row2"),c("C.1", "C.2", "C.3"))) mdat[2, ] 表示选取矩阵第1行元素mdat[, 2] 表示选取矩阵第2列元素mdat[1, 2] 表示选取矩阵第1行第2列元素mdat[1, c(1, 2)] 表示选取矩阵第1行的第1个第2个元素
4 数组
数组使用array进行创建,与向量或矩阵不同的是,array可以是多维的。array中的数据一样是相同mode的,array函数的像是以下:
array(data = NA, dim = length(data), dimnames = NULL),其中vector包括array中的元素,dim是1个向量指定array各个维度的大小,dimnames是1个list指定各个维度对应的名称。5 数据框:dim1 <- c("A1", "A2")
dim2 <- c("B1", "B2", "B3")
dim3 <- c("C1", "C2", "C3", "C4")
z <- array(1:24, c(2, 3, 4), list(dim1, dim2, dim3))
z[1,2,3] 为 15 表示选取 x=1 y=2 z=3 的值,只有这1种选取方式
数据框是我们经常使用的进行数据分析的数据存储方式,和数据库的每行对应1个记录,每列对应1个字段,数据框使用data.frame(name1=col1, name2=col2,...)进行创建,注意是列主导。
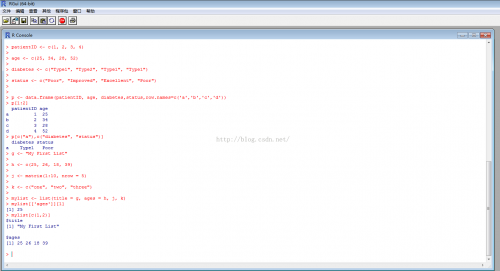
patientID <- c(1, 2, 3, 4)
age <- c(25, 34, 28, 52)
diabetes <- c("Type1", "Type2", "Type1", "Type1")
status <- c("Poor", "Improved", "Excellent", "Poor")
p <- data.frame(patientID, age, diabetes,status,row.names=c('a','b','c','d'))
p[1:2] 表示选取第1列第2列数据
p[c("a"),c("diabetes", "status")] 选取列表为"diabetes", "status",行名为"a"的数据
6 列表:
据类型中最为复杂的1种。1般来讲,列表就是1些对象(或成份,component)的有序集合。列表允许你整合若干(可能无关的)对象到单个对象名下。例如,某个列表中多是若干向量、矩阵、数据框,乃至其他列表的组合。列表和Python中的dict很像,使用list进行创建,是行动主导的,list的情势为list(name1=object1, name2=object2,...)。
g <- "My First List"
h <- c(25, 26, 18, 39)
j <- matrix(1:10, nrow = 5)
k <- c("one", "two", "three")
mylist <- list(title = g, ages = h, j, k)
mylist[['ages']][1] 获得名称ages的元素的第1个数据
mylist[c(1,2)] 取得第1个元素和第2个元素
实操进程以下:
版权声明:本文为博主原创文章,未经博主允许不得转载。