[置顶] 你的java/c/c++程序崩溃了?揭秘段错误(Segmentation fault)(3)
前言
接上两篇:
你的C/C++程序为何没法运行?揭秘Segmentation fault (1)
你的C/C++程序为何没法运行?揭秘Segmentation fault (2)
写到这里,越跟,越发现真的是内核上很白,非1般的白。
但是既然是研究,就定住心,把段毛病弄到清楚明白。
本篇将作为终篇,来结束这个系列,也算是对段毛病和程序调试、寻觅崩溃缘由(通常不会给你那末完善的stackstrace和人性化的毛病提示)的再深入。
本篇使用到的工具或命令:
- dmesg
- strace
- gdb
- linux 内核3.10源码
情形再现
上两篇围绕着1个这样的问题进行展开:
//野指针
char ** p;
//零指针或空指针
p = NULL;
//段毛病(Segmentation Fault)
*p = (char *)malloc(sizeof(char));问题代码
为了本篇的可读性,围绕上述问题编织问题代码:
#include "stdio.h"
#include "string.h"
#include "stdlib.h"
int main(int argc,char** args) {
char * p = NULL;
*p = 0x0;
}段毛病

找出问题
第1步 strace 查信号描写
上篇已介绍了gbd+coredump的方法来找到出现段毛病的代码,本篇直接上strace:
strace -i -x -o segfault.txt ./segfault.o得到以下信息:

可以知道:
1.毛病信号:SIGSEGV
3.毛病码:SEGV_MAPERR
3.毛病内存地址:0x0
4.逻辑地址0x400507处出错.
可以猜想:
程序中有空指针访问试图向
0x0写入而引发段毛病.
第2步 dmesg 查毛病现场
上dmesg:
dmesg得到:

可知:
1.毛病类型:segfault ,即段毛病(Segmentation Fault).
2.出错时ip:0x400507
3.毛病号:6,即110
第3步 搜集已知结论
这里 毛病号和ip 是关键,毛病号对比下面:
/*
* Page fault error code bits:
*
* bit 0 == 0: no page found 1: protection fault
* bit 1 == 0: read access 1: write access
* bit 2 == 0: kernel-mode access 1: user-mode access
* bit 3 == 1: use of reserved bit detected
* bit 4 == 1: fault was an instruction fetch
*/
/*enum x86_pf_error_code {
PF_PROT = 1 << 0,
PF_WRITE = 1 << 1,
PF_USER = 1 << 2,
PF_RSVD = 1 << 3,
PF_INSTR = 1 << 4,
};*/对比后可知:
毛病号6 = 110 = (PF_USER | PF_WIRTE | 0).
即“用户态”、“写入型页毛病 ”、“没有与指定的地址相对应的页”.
上面的信息与我们最初的推断吻合.
现在,对目前已知结论进行概括以下:
1.毛病类型:segfualt ,即段毛病(Segmentation Fault).
2.出错时ip:0x400507
3.毛病号:6,即110
4.毛病码:SEGV_MAPERR 即地址没有映照到对象.
5.毛病缘由:对
0x0进行写操作引发了段毛病,缘由是0x0没有与之对应的页或叫映照.
第4步 根据结论找到出错代码
上gdb:
gdb ./segfault.o根据结论中的ip = 0x400507立即得到:
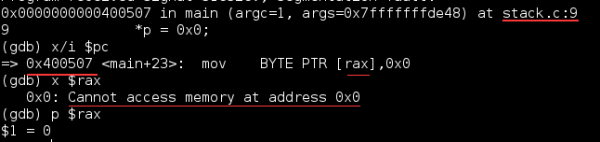
明显,这验证了我们的结论:
我们试图将值
0x0写入地址0x0从而引发写入未映照的地址的段毛病.
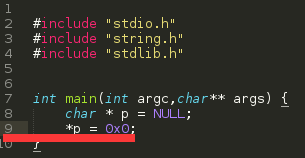 并且我们找到了毛病的代码stack.c的第9行:
并且我们找到了毛病的代码stack.c的第9行:
查根溯源
明显,我们不满足于此,为何访问了0x0会造成这个毛病从而让程序崩溃?
第2篇已说了进程虚拟地址空间的问题,事实上我们进行写入操作的时候,会引发虚拟地址到物理地址的映照,由于你终究要将数据(本篇是0x0,注意和我们的地址0x0辨别)写入到物理内存中。
0x0是个逻辑地址,linux按页式管理内存映照,0x0不会对应任何页,那末内存中就不会有主页,所以对其进行写入就会引发1个缺页中断,这1部份由linux内存映照管理模块(memory mapping,缩写mm)处理。
缺页毛病处理
1. __do_page_fault
缺页落后入__do_page_fault流程,注意,这里为了尽可能减少篇幅,删去了源代码的1些注释,而与我们有关的命中代码都做了注释:
/*
* This routine handles page faults. It determines the address,
* and the problem, and then passes it off to one of the appropriate
* routines.
*/
static void __kprobes
__do_page_fault(struct pt_regs *regs, unsigned long error_code./* 注意我们的毛病是6,即110 */)
{
struct vm_area_struct *vma;
struct task_struct *tsk;
unsigned long address;
struct mm_struct *mm;
int fault;
int write = error_code & PF_WRITE;
unsigned int flags = FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_KILLABLE |
(write ? FAULT_FLAG_WRITE : 0);
tsk = current;
mm = tsk->mm;
/* 这里会去取到我们的 地址=0x0 */
/* Get the faulting address: */
address = read_cr2();
if (kmemcheck_active(regs))
kmemcheck_hide(regs);
prefetchw(&mm->mmap_sem);
if (unlikely(kmmio_fault(regs, address)))
return;
if (unlikely(fault_in_kernel_space(address))) {
//这里略去,不会命中
/* ... */
return;
}
//略去很多代码
// ...
retry:
down_read(&mm->mmap_sem);
} else {
might_sleep();
}
vma = find_vma(mm, address);
if (unlikely(!vma)) {
/* 到这里处理 */
bad_area(regs, error_code, address);
//处理后返回
return;
}
//略去很多代码
// ...
}2. bad_area
其中的1个关键调用bad_area(regs, error_code, address);
static noinline void
bad_area(struct pt_regs *regs, unsigned long error_code, unsigned long address)
{
/* 注意这里讲毛病码设为了SEGV_MAPERR */
__bad_area(regs, error_code, address, SEGV_MAPERR);
}可以明确
我们结论中的SEGV_MAPERR的出处.
这个类型就是没法映照到对象的意思!看下面strace得到的东西,其中
si_code=SEGV_MAPERR.--- SIGSEGV {si_signo=SIGSEGV, si_code=SEGV_MAPERR, si_addr=0} --- +++ killed by SIGSEGV (core dumped) +++
最后会来到这里:
static void
__bad_area_nosemaphore(struct pt_regs *regs, unsigned long error_code,
unsigned long address, int si_code)
{
struct task_struct *tsk = current;
/* 我们的毛病码是6 = 110,PF_USER = 100,所以会进入这个if */
if (error_code & PF_USER) {
/* 关中断 */
local_irq_enable();
//...略
if (address >= TASK_SIZE)
error_code |= PF_PROT;
/* 这里会将出错信息打印 */
if (likely(show_unhandled_signals))
show_signal_msg(regs, error_code, address, tsk);
tsk->thread.cr2 = address;
tsk->thread.error_code = error_code;
tsk->thread.trap_nr = X86_TRAP_PF;
/* 这里会强迫发送 SIGSEGV=段毛病 信号 */
force_sig_info_fault(SIGSEGV, si_code, address, tsk, 0);
return;
}
//...略
}注意上面的代码的两个关键调用:
show_signal_msg //用于打印出错信息
force_sig_info_fault //用于强迫发送信号3. show_signal_msg
/*
* Print out info about fatal segfaults, if the show_unhandled_signals
* sysctl is set:
*/
static inline void
show_signal_msg(struct pt_regs *regs, unsigned long error_code,
unsigned long address, struct task_struct *tsk)
{
//...略
/* 打印段毛病信息 -> /proc/kmsg */
printk("%s%s[%d]: segfault at %lx ip %p sp %p error %lx",
task_pid_nr(tsk) > 1 ? KERN_INFO : KERN_EMERG,
tsk->comm, task_pid_nr(tsk), address,
(void *)regs->ip, (void *)regs->sp, error_code);
print_vma_addr(KERN_CONT " in ", regs->ip);
printk(KERN_CONT "
");
}其中,打印段毛病的信息的代码,就是我们使用dmesg得到的东西.
可以对照下我们的段毛病的图:

4. force_sig_info_fault
最后就是发送信号了。
static void
force_sig_info_fault(int si_signo, int si_code, unsigned long address,
struct task_struct *tsk, int fault)
{
unsigned lsb = 0;
siginfo_t info;
info.si_signo = si_signo;
info.si_errno = 0;
info.si_code = si_code;
info.si_addr = (void __user *)address;
if (fault & VM_FAULT_HWPOISON_LARGE)
lsb = hstate_index_to_shift(VM_FAULT_GET_HINDEX(fault));
if (fault & VM_FAULT_HWPOISON)
lsb = PAGE_SHIFT;
info.si_addr_lsb = lsb;
/* 强迫发送SIGSEGV信号 */
force_sig_info(si_signo, &info, tsk);
}force_sig_info:
int
force_sig_info(int sig, struct siginfo *info, struct task_struct *t)
{
unsigned long int flags;
int ret, blocked, ignored;
struct k_sigaction *action;
spin_lock_irqsave(&t->sighand->siglock, flags);
/* 这里就指定信号的处理程序了 */
action = &t->sighand->action[sig-1];
//...略
/* 必须强迫发送 */
if (action->sa.sa_handler == SIG_DFL)
/* 不需要递归式的发送SEGSIGV信号,所以清掉SIGNAL_UNKILLABLE */
t->signal->flags &= ~SIGNAL_UNKILLABLE;
// 发送
ret = specific_send_sig_info(sig, info, t);
spin_unlock_irqrestore(&t->sighand->siglock, flags);
return ret;
}上面的代码告知我们,信号的处理程序如何被指定的,那末关于段毛病的信号SEGSIGV默许就是core dump.
5. core dump
到此,我们已可以拿到core dump,那末第2篇中找到引发段毛病的代码的方法就能够用了,这也是推荐的做法:
gdb ./segfault.o core.36054
是否是立便可知stack.c第9行的代码*p = 0x0是罪魁罪魁了呢?
结语
到此,全部段毛病的探索就结束了,希望读者和我1样不枉此行。
列出几种常见段毛病缘由:
1.数组越界
int a[10] = {0,1};
printf("%d",a[10000]);2.零指针或空指针
//本系列所用实例
char * p = NULL;
*p = 0x0;3.悬浮指针
如果指针p悬浮,它指向的地址有可能能用,也有可能不能,你不知道那块地址甚么时候被写入,甚么时候被保护(mprotect).
如果被保护为可读,你写就出现段毛病!
4.访问权限,非法访问
参见3.
5.多线程对同享指针变量操作
不但c/c++,android中、java程序中有可能也会出现jvm崩溃哦,那检查下多线程的同享变量吧!
如有毛病,请不吝赐教.