转载请注明出处:http://blog.csdn.net/luotuo44/article/details/42963793
温馨提示:本文用到了1些可以在启动memcached设置的全局变量。关于这些全局变量的含义可以参考《memcached启动参数详解》。对这些全局变量,处理方式就像《如何浏览memcached源代码》所说的那样直接取其默许值。
过期失效处理:
1个item在两种情况下会过期失效:1.item的exptime时间戳到了。2.用户使用flush_all命令将全部item变成过期失效的。读者可能会说touch命令也能够使得1个item过期失效,其实这也属于前面说的第1种情况。
超时失效:
对第1种过期失效,memcached的使用怠惰处理:不主动检测1个item是不是过期失效。当worker线程访问这个item时,才检测这个item的exptime时间戳是不是到了。比较简单,这里就先不贴代码,后面会贴。
flush_all命令:
第2种过期失效是用户flush_all命令设置的。flush_all会将所有item都变成过期失效。所有item是指哪些item?由于多个客户端会不断地往memcached插入item,所以必须要明白所有item是指哪些。是以worker线程接收到这个命令那1刻为界?还是以删除那1刻为界?
当worker线程接收到flush_all命令后,会用全局变量settings的oldest_live成员存储接收到这个命令那1刻的时间(准确地说,是worker线程解析得知这是1个flush_all命令那1刻再减1),代码为settings.oldest_live =current_time - 1;然后调用item_flush_expired函数锁上cache_lock,然后调用do_item_flush_expired函数完成工作。
void do_item_flush_expired(void) {
int i;
item *iter, *next;
if (settings.oldest_live == 0)
return;
for (i = 0; i < LARGEST_ID; i++) {
for (iter = heads[i]; iter != NULL; iter = next) {
if (iter->time != 0 && iter->time >= settings.oldest_live) {
next = iter->next;
if ((iter->it_flags & ITEM_SLABBED) == 0) {
do_item_unlink_nolock(iter, hash(ITEM_key(iter), iter->nkey));
}
} else {
/* We've hit the first old item. Continue to the next queue. */
break;
}
}
}
}
do_item_flush_expired函数内部会变量所有LRU队列,检测每个item的time成员。检测time成员是公道的。如果time成员小于settings.oldest_live就说明该item在worker线程接收到flush_all命令的时候就已存在了(time成员表示该item的最后1次访问时间)。那末就该删除这个item。
这样看来memcached是以worker线程接收到flush_all命令那1刻为界的。等等等等,看清楚1点!!在do_item_flush_expired函数里面,不是当item的time成员小于settings.oldest_live时删除这个item,而是大于的时候才删除。从time成员变量的意义来讲,大于代表甚么啊?有大于的吗?奇怪!@#@&¥
实际上memcached是以删除那1刻为界的。那settings.oldest_live为何要存储worker线程接收到flush_all命令的时间戳?为何又要判断iter->time是不是大于settings.oldest_live呢?
依照1般的做法,在do_item_flush_expired函数中直接把哈希表和LRU上的所有item统统删除便可。这样确切是可以到达目标。但在本worker线程处理期间,其他worker线程完全不能工作(由于do_item_flush_expired的调用者已锁上了cache_lock)。而LRU队列里面可能有大量的数据,这个过期处理进程可能会很长。其他worker线程完全不能工作是难于接受的。
memcached的作者肯定也意想到这个问题,所以他就写了1个奇怪的do_item_flush_expired函数,用来加速。do_item_flush_expired只会删除少许特殊的item。如何特殊法,在后面代码注释中会解释。对其他大量的item,memcached采取怠惰方式处理。只有当worker线程试图访问该item,才检测item是不是已被设置为过期的了。事实上,无需对item进行任何设置就可以检测该item是不是为过期的,通过settings.oldest_live变量便可。这类怠惰和前面第1种item过期失效的处理是1样的。
现在再看1下do_item_flush_expired函数,看1下特殊的item。
void do_item_flush_expired(void) {
int i;
item *iter, *next;
if (settings.oldest_live == 0)
return;
for (i = 0; i < LARGEST_ID; i++) {
for (iter = heads[i]; iter != NULL; iter = next) {
//iter->time == 0的是lru爬虫item,直接疏忽
//1般情况下iter->time是小于settings.oldest_live的。但在这类情况下
//就有可能出现iter->time >= settings.oldest_live : worker1接收到
//flush_all命令,并给settings.oldest_live赋值为current_time⑴。
//worker1线程还没来得及调用item_flush_expired函数,就被worker2
//抢占了cpu,然后worker2往lru队列插入了1个item。这个item的time
//成员就会满足iter->time >= settings.oldest_live
if (iter->time != 0 && iter->time >= settings.oldest_live) {
next = iter->next;
if ((iter->it_flags & ITEM_SLABBED) == 0) {
//虽然调用的是nolock,但本函数的调用者item_flush_expired
//已锁上了cache_lock,才调用本函数的
do_item_unlink_nolock(iter, hash(ITEM_key(iter), iter->nkey));
}
} else {
//由于lru队列里面的item是根据time降序排序的,所以当存在1个item的time成员
//小于settings.oldest_live,剩下的item都不需要再比较了
break;
}
}
}
}
怠惰删除:
现在来看1下item的怠惰删除。注意代码中的注释。
item *do_item_get(const char *key, const size_t nkey, const uint32_t hv) {
item *it = assoc_find(key, nkey, hv);
...
if (it != NULL) {
//settings.oldest_live初始化值为0
//检测用户是不是使用过flush_all命令,删除所有item。
//it->time <= settings.oldest_live就说明用户在使用flush_all命令的时候
//就已存在该item了。那末该item是要删除的。
//flush_all命令可以有参数,用来设定在未来的某个时刻把所有的item都设置
//为过期失效,此时settings.oldest_live是1个比worker接收到flush_all
//命令的那1刻大的时间,所以要判断settings.oldest_live <= current_time
if (settings.oldest_live != 0 && settings.oldest_live <= current_time &&
it->time <= settings.oldest_live) {
do_item_unlink(it, hv);
do_item_remove(it);
it = NULL;
} else if (it->exptime != 0 && it->exptime <= current_time) {//该item已过期失效了
do_item_unlink(it, hv);//援用数会减1
do_item_remove(it);//援用数减1,如果援用数等于0,就删除
it = NULL;
} else {
it->it_flags |= ITEM_FETCHED;
}
}
return it;
}
可以看到,在查找到1个item后就要检测它是不是过期失效了。失效了就要删除之。
除do_item_get函数外,do_item_alloc函数也是会处理过期失效item的。do_item_alloc函数不是删除这个过期失效item,而是占为己用。由于这个函数的功能是申请1个item,如果1个item过期了那末就直接霸占这个item的那块内存。下面看1下代码。
item *do_item_alloc(char *key, const size_t nkey, const int flags,
const rel_time_t exptime, const int nbytes,
const uint32_t cur_hv) {
uint8_t nsuffix;
item *it = NULL;
char suffix[40];
//要存储这个item需要的总空间
size_t ntotal = item_make_header(nkey + 1, flags, nbytes, suffix, &nsuffix);
if (settings.use_cas) {
ntotal += sizeof(uint64_t);
}
//根据大小判断从属于哪一个slab
unsigned int id = slabs_clsid(ntotal);
/* do a quick check if we have any expired items in the tail.. */
int tries = 5;
item *search;
item *next_it;
rel_time_t oldest_live = settings.oldest_live;
search = tails[id];
for (; tries > 0 && search != NULL; tries--, search=next_it) {
next_it = search->prev;
...
if (refcount_incr(&search->refcount) != 2) {//援用数,还有其他线程在援用,不能霸占这个item
//刷新这个item的访问时间和在LRU队列中的位置
do_item_update_nolock(search);
tries++;
refcount_decr(&search->refcount);
//此时援用数>=2
continue;
}
//search指向的item的refcount等于2,这说明此时这个item除本worker
//线程外,没有其他任何worker线程索引其。可以放心释放并重用这个item
//由于这个循环是从lru链表的后面开始遍历的。所以1开始search就指向
//了最不经常使用的item,如果这个item都没有过期。那末其他的比其更经常使用
//的item就不要删除(即便它们过期了)。此时只能向slabs申请内存
if ((search->exptime != 0 && search->exptime < current_time)
|| (search->time <= oldest_live && oldest_live <= current_time)) {
//search指向的item是1个过期失效的item,可使用之
it = search;
//重新计算1下这个slabclass_t分配出去的内存大小
//直接霸占旧的item就需要重新计算
slabs_adjust_mem_requested(it->slabs_clsid, ITEM_ntotal(it), ntotal);
do_item_unlink_nolock(it, hv);//从哈希表和lru链表中删除
/* Initialize the item block: */
it->slabs_clsid = 0;
}
//援用计数减1。此时该item已没有任何worker线程索引其,并且哈希表也
//不再索引其
refcount_decr(&search->refcount);
break;
}
...
return it;
}
//新的item直接霸占旧的item就会调用这个函数
void slabs_adjust_mem_requested(unsigned int id, size_t old, size_t ntotal)
{
pthread_mutex_lock(&slabs_lock);
slabclass_t *p;
if (id < POWER_SMALLEST || id > power_largest) {
fprintf(stderr, "Internal error! Invalid slab class
");
abort();
}
p = &slabclass[id];
//重新计算1下这个slabclass_t分配出去的内存大小
p->requested = p->requested - old + ntotal;
pthread_mutex_unlock(&slabs_lock);
}
flush_all命令是可以有时间参数的。这个时间和其他时间1样取值范围是 1到REALTIME_MAXDELTA(30天)。如果命令为flush_all 100,那末99秒后所有的item失效。此时settings.oldest_live的值为current_time+100⑴,do_item_flush_expired函数也没有甚么用了(总不会被抢占CPU99秒吧)。也正是这个缘由,需要在do_item_get里面,加入settings.oldest_live<= current_time这个判断,避免过早删除item。
这里明显有1个bug。假设客户端A向服务器提交了flush_all10命令。过了5秒后,客户端B向服务器提交命令flush_all100。那末客户端A的命令将失效,没有起到任何作用。
LRU爬虫:
前面说到,memcached是怠惰删除过期失效item的。所以即便用户在客户端使用了flush_all命令使得全部item都过期失效了,但这些item还是占据者哈希表和LRU队列并没有归还给slab分配器。
LRU爬虫线程:
有无办法强迫清除这些过期失效的item,不再占据哈希表和LRU队列的空间并归还给slabs呢?固然是有的。memcached提供了LRU爬虫可以实现这个功能。
要使用LRU爬虫就必须在客户端使用lru_crawler命令。memcached服务器根据具体的命令参数进行处理。
memcached是用1个专门的线程负责清除这些过期失效item的,本文将称这个线程为LRU爬虫线程。默许情况下memcached是不启动这个线程的,但可以在启动memcached的时候添加参数-o lru_crawler启动这个线程。也能够通过客户端命令启动。即便启动了这个LRU爬虫线程,该线程还是不会工作。需要另外发送命令,指明要对哪一个LRU队列进行清除处理。现在看1下lru_crawler有哪些参数。
LRU爬虫命令:
- lru_crawler <enable|disable> 启动或停止1个LRU爬虫线程。任什么时候刻,最多只有1个LRU爬虫线程。该命令对settings.lru_crawler进行赋值为true或false
- lru_crawler crawl <classid,classid,classid|all> 可使用2,3,6这样的列表指明要对哪一个LRU队列进行清除处理。也能够使用all对所有的LRU队列进行处理
- lru_crawler sleep <microseconds> LRU爬虫线程在清除item的时候会占用锁,会妨碍worker线程的正常业务。所以LRU爬虫在处理的时候需要时不时休眠1下。默许休眠时间为100微秒。该命令对settings.lru_crawler_sleep进行赋值
- lru_crawler tocrawl <32u> 1个LRU队列可能会有很多过期失效的item。如果1直检查和清除下去,必将会妨碍worker线程的正常业务。这个参数用来指明最多只检查每条LRU队列的多少个item。默许值为0,所以如果不指定那末就不会工作。该命令对settings.lru_crawler_tocrawl进行赋值
如果要启动LRU爬虫主动删除过期的item,需要这样做:首先使用lru_crawlerenable命令启动1个LRU爬虫线程。然后使用lru_crawlertocrawl num命令肯定每个LRU队列最多检查num⑴个item。最后使用命令lru_crawlercrawl <classid,classid,classid|all>
指定要处理的LRU队列。lru_crawler sleep可以不设置,如果要设置那末可以在lru_crawler crawl命令之前设置便可。
启动LRU爬虫线程:
现在来看1下LRU爬虫是怎样工作的。先来看1下memcached为LRU爬虫定义了哪些全局变量。
static volatile int do_run_lru_crawler_thread = 0;
static int lru_crawler_initialized = 0;
static pthread_mutex_t lru_crawler_lock = PTHREAD_MUTEX_INITIALIZER;
static pthread_cond_t lru_crawler_cond = PTHREAD_COND_INITIALIZER;
int init_lru_crawler(void) {//main函数会调用该函数
if (lru_crawler_initialized == 0) {
if (pthread_cond_init(&lru_crawler_cond, NULL) != 0) {
fprintf(stderr, "Can't initialize lru crawler condition
");
return ⑴;
}
pthread_mutex_init(&lru_crawler_lock, NULL);
lru_crawler_initialized = 1;
}
return 0;
}
代码比较简单,这里就不说了。下面看1下lru_crawler enable和disable命令。enable命令会启动1个LRU爬虫线程,而disable会停止这个LRU爬虫线程,固然不是直接调用pthread_exit停止线程。pthread_exit函数是1个危险函数,不应当在代码出现。
static pthread_t item_crawler_tid;
//worker线程接收到"lru_crawler enable"命令后会调用本函数
//启动memcached时如果有-o lru_crawler参数也是会调用本函数
int start_item_crawler_thread(void) {
int ret;
//在stop_item_crawler_thread函数可以看到pthread_join函数
//在pthread_join返回后,才会把settings.lru_crawler设置为false。
//所以不会出现同时出现两个crawler线程
if (settings.lru_crawler)
return ⑴;
pthread_mutex_lock(&lru_crawler_lock);
do_run_lru_crawler_thread = 1;
settings.lru_crawler = true;
//创建1个LRU爬虫线程,线程函数为item_crawler_thread。LRU爬虫线程在进入
//item_crawler_thread函数后,会调用pthread_cond_wait,等待worker线程指定
//要处理的LRU队列
if ((ret = pthread_create(&item_crawler_tid, NULL,
item_crawler_thread, NULL)) != 0) {
fprintf(stderr, "Can't create LRU crawler thread: %s
",
strerror(ret));
pthread_mutex_unlock(&lru_crawler_lock);
return ⑴;
}
pthread_mutex_unlock(&lru_crawler_lock);
return 0;
}
//worker线程在接收到"lru_crawler disable"命令会履行这个函数
int stop_item_crawler_thread(void) {
int ret;
pthread_mutex_lock(&lru_crawler_lock);
do_run_lru_crawler_thread = 0;//停止LRU线程
//LRU爬虫线程可能休眠于等待条件变量,需要唤醒才能停止LRU爬虫线程
pthread_cond_signal(&lru_crawler_cond);
pthread_mutex_unlock(&lru_crawler_lock);
if ((ret = pthread_join(item_crawler_tid, NULL)) != 0) {
fprintf(stderr, "Failed to stop LRU crawler thread: %s
", strerror(ret));
return ⑴;
}
settings.lru_crawler = false;
return 0;
}
可以看到worker线程在接收到” lru_crawler enable”命令后会启动1个LRU爬虫线程。这个LRU爬虫线程还没去履行任务,由于还没有指定任务。命令"lru_crawlertocrawl num"其实不是启动1个任务。对这个命令,worker线程只是简单地把settings.lru_crawler_tocrawl赋值为num。
清除失效item:
命令”lru_crawler crawl<classid,classid,classid|all>”才是指定任务的。该命令指明了要对哪一个LRU队列进行清算。如果使用all那末就是对所有的LRU队列进行清算。
在看memcached的清算代码之前,先斟酌1个问题:怎样对1条LRU队列进行清算?
最直观的做法是先加锁(锁上cache_lock),然后遍历1整条LRU队列。直接判断LRU队列里面的每个item便可。明显这类方法有问题。如果memcached有大量的item,那末遍历1个LRU队列耗时将太久。这样会妨碍worker线程的正常业务。固然我们可以斟酌使用分而治之的方法,每次只处理几个item,屡次进行,终究到达处理全部LRU队列的目标。但LRU队列是1个链表,不支持随机访问。处理队列中间的某个item,需要从链表头或尾顺次访问,时间复杂度还是O(n)。
伪item:
memcached为了实现随机访问,使用了1个很奇妙的方法。它在LRU队列尾部插入1个伪item,然后驱动这个伪item向队列头部前进,每次前进1位。
这个伪item是全局变量,LRU爬虫线程不必从LRU队列头部或尾部遍历就能够直接访问这个伪item。通过这个伪item的next和prev指针,就能够访问真实的item。因而,LRU爬虫线程无需遍历就能够直接访问LRU队列中间的某1个item。
下面看1下lru_crawler_crawl函数,memcached会在这个函数会把伪item插入到LRU队列尾部的。当worker线程接收到lru_crawler crawl<classid,classid,classid|all>命令时就会调用这个函数。由于用户可能要求LRU爬虫线程清算多个LRU队列的过期失效item,所以需要1个伪item数组。伪item数组的大小等于LRU队列的个数,它们是逐一对应的。
//这个结构体和item结构体长得很像,是伪item结构体,用于LRU爬虫
typedef struct {
struct _stritem *next;
struct _stritem *prev;
struct _stritem *h_next; /* hash chain next */
rel_time_t time; /* least recent
access */
rel_time_t exptime; /* expire time */
int nbytes; /* size of data */
unsigned short refcount;
uint8_t nsuffix; /* length of flags-and-length string */
uint8_t it_flags; /* ITEM_* above */
uint8_t slabs_clsid;/* which slab class we're in */
uint8_t nkey; /* key length, w/terminating null and padding */
uint32_t remaining; /* Max keys to crawl per slab per invocation */
} crawler;
static crawler crawlers[LARGEST_ID];
static int crawler_count = 0;//本次任务要处理多少个LRU队列
//当客户端使用命令lru_crawler crawl <classid,classid,classid|all>时,
//worker线程就会调用本函数,并将命令的第2个参数作为本函数的参数
enum crawler_result_type lru_crawler_crawl(char *slabs) {
char *b = NULL;
uint32_t sid = 0;
uint8_t tocrawl[POWER_LARGEST];
//LRU爬虫线程进行清算的时候,会锁上lru_crawler_lock。直到完成所有
//的清算任务才会解锁。所以客户真个前1个清算任务还没结束前,不能
//再提交另外1个清算任务
if (pthread_mutex_trylock(&lru_crawler_lock) != 0) {
return CRAWLER_RUNNING;
}
pthread_mutex_lock(&cache_lock);
//解析命令,如果命令要求对某1个LRU队列进行清算,那末就在tocrawl数组
//对应元素赋值1作为标志
if (strcmp(slabs, "all") == 0) {//处理全部lru队列
for (sid = 0; sid < LARGEST_ID; sid++) {
tocrawl[sid] = 1;
}
} else {
for (char *p = strtok_r(slabs, ",", &b);
p != NULL;
p = strtok_r(NULL, ",", &b)) {
//解析出1个个的sid
if (!safe_strtoul(p, &sid) || sid < POWER_SMALLEST
|| sid > POWER_LARGEST) {//sid越界
pthread_mutex_unlock(&cache_lock);
pthread_mutex_unlock(&lru_crawler_lock);
return CRAWLER_BADCLASS;
}
tocrawl[sid] = 1;
}
}
//crawlers是1个伪item类型数组。如果用户要清算某1个LRU队列,那末
//就在这个LRU队列中插入1个伪item
for (sid = 0; sid < LARGEST_ID; sid++) {
if (tocrawl[sid] != 0 && tails[sid] != NULL) {
//对伪item和真实的item,可以用nkey、time这两个成员的值区分
crawlers[sid].nbytes = 0;
crawlers[sid].nkey = 0;
crawlers[sid].it_flags = 1; /* For a crawler, this means enabled. */
crawlers[sid].next = 0;
crawlers[sid].prev = 0;
crawlers[sid].time = 0;
crawlers[sid].remaining = settings.lru_crawler_tocrawl;
crawlers[sid].slabs_clsid = sid;
//将这个伪item插入到对应的lru队列的尾部
crawler_link_q((item *)&crawlers[sid]);
crawler_count++;//要处理的LRU队列数加1
}
}
pthread_mutex_unlock(&cache_lock);
//有任务了,唤醒LRU爬虫线程,让其履行清算任务
pthread_cond_signal(&lru_crawler_cond);
STATS_LOCK();
stats.lru_crawler_running = true;
STATS_UNLOCK();
pthread_mutex_unlock(&lru_crawler_lock);
return CRAWLER_OK;
}
现在再来看1下伪item是怎样在LRU队列中前进的。先看1个伪item前进图。
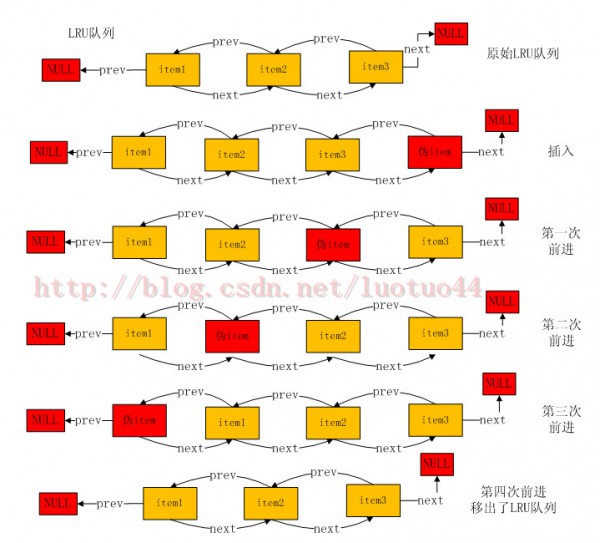
从上面的图可以看到,伪item通过与先驱节点交换位置实现前进。如果伪item是LRU队列的头节点,那末就将这个伪item移出LRU队列。函数crawler_crawl_q完成这个交换操作,并且返回交换前伪item的先驱节点(固然在交换后就变成伪item的后驱节点了)。如果伪item处于LRU队列的头部,那末就返回NULL(此时没有先驱节点了)。crawler_crawl_q函数里面那些指针满天飞,这里就不贴出代码了。
上面的图,虽然伪item遍历了LRU队列,但并没有删除某个item。这样画,1来是为了好看,2来遍历LRU队列不1定会删除item的(item不过期失效就不会删除)。
清算item:
前面说到,可以用命令lru_crawler tocrawl num指定每一个LRU队列最多只检查num⑴个item。看清楚点,是检查数,不是删除数,而且是num⑴个。首先要调用item_crawler_evaluate函数检查1个item是不是过期,是的话就删除。如果检查完num⑴个,伪item都还没有到达LRU队列的头部,那末就直接将这个伪item从LRU队列中删除。下面看1下item_crawler_thread函数吧。
static void *item_crawler_thread(void *arg) {
int i;
pthread_mutex_lock(&lru_crawler_lock);
while (do_run_lru_crawler_thread) {
//lru_crawler_crawl函数和stop_item_crawler_thread函数会signal这个条件变量
pthread_cond_wait(&lru_crawler_cond, &lru_crawler_lock);
while (crawler_count) {//crawler_count表明要处理多少个LRU队列
item *search = NULL;
void *hold_lock = NULL;
for (i = 0; i < LARGEST_ID; i++) {
if (crawlers[i].it_flags != 1) {
continue;
}
pthread_mutex_lock(&cache_lock);
//返回crawlers[i]的先驱节点,并交换crawlers[i]和先驱节点的位置
search = crawler_crawl_q((item *)&crawlers[i]);
if (search == NULL || //crawlers[i]是头节点,没有先驱节点
//remaining的值为settings.lru_crawler_tocrawl。每次启动lru
//爬虫线程,检查每个lru队列的多少个item。
(crawlers[i].remaining && --crawlers[i].remaining < 1)) {
//检查了足够屡次,退出检查这个lru队列
crawlers[i].it_flags = 0;
crawler_count--;//清算完1个LRU队列,任务数减1
crawler_unlink_q((item *)&crawlers[i]);//将这个伪item从LRU队列中删除
pthread_mutex_unlock(&cache_lock);
continue;
}
uint32_t hv = hash(ITEM_key(search), search->nkey);
//尝试锁住控制这个item的哈希表段级别锁
if ((hold_lock = item_trylock(hv)) == NULL) {
pthread_mutex_unlock(&cache_lock);
continue;
}
//此时有其他worker线程在援用这个item
if (refcount_incr(&search->refcount) != 2) {
refcount_decr(&search->refcount);//lru爬虫线程放弃援用该item
if (hold_lock)
item_trylock_unlock(hold_lock);
pthread_mutex_unlock(&cache_lock);
continue;
}
//如果这个item过期失效了,那末就删除这个item
item_crawler_evaluate(search, hv, i);
if (hold_lock)
item_trylock_unlock(hold_lock);
pthread_mutex_unlock(&cache_lock);
//lru爬虫不能不中断地爬lru队列,这样会妨碍worker线程的正常业务
//所以需要挂起lru爬虫线程1段时间。在默许设置中,会休眠100微秒
if (settings.lru_crawler_sleep)
usleep(settings.lru_crawler_sleep);//微秒级
}
}
STATS_LOCK();
stats.lru_crawler_running = false;
STATS_UNLOCK();
}
pthread_mutex_unlock(&lru_crawler_lock);
return NULL;
}
//如果这个item过期失效了,那末就删除其
static void item_crawler_evaluate(item *search, uint32_t hv, int i) {
rel_time_t oldest_live = settings.oldest_live;
//这个item的exptime时间戳到了,已过期失效了
if ((search->exptime != 0 && search->exptime < current_time)
//由于客户端发送flush_all命令,致使这个item失效了
|| (search->time <= oldest_live && oldest_live <= current_time)) {
itemstats[i].crawler_reclaimed++;
if ((search->it_flags & ITEM_FETCHED) == 0) {
itemstats[i].expired_unfetched++;
}
//将item从LRU队列中删除
do_item_unlink_nolock(search, hv);
do_item_remove(search);
assert(search->slabs_clsid == 0);
} else {
refcount_decr(&search->refcount);
}
}
真实的LRU淘汰:
虽然本文前面屡次使用LRU这个词,并且memcached代码里面的函数命名也用了lru前缀,特别是lru_crawler命令。但实际上这和LRU淘汰没有半毛钱关系!!
上当受骗了吧,骂吧:¥&@#¥&*@%##……%#%……#¥%¥@#%……
读者可以回想1下操作系统里面的LRU算法。本文里面删除的那些item都是过期失效的,删除活该。过期了还霸着位置,有点像霸着茅坑不拉屎。操作系统里面LRU算法是由于资源不够,迫于无奈而被踢的,被踢者也是挺无奈的。不1样吧,所以说本文前面说的不是LRU。
那memcached的LRU在哪里体现了呢?do_item_alloc函数!!前面的博文1直都有提到这个神1般的函数,但从没有给出完全的版本。固然这里也不会给出完全的版本。由于这个函数里面还是有1些东西暂时没法解释给读者们听。现在估计读者都能体会到《如何浏览memcached源码》中写到的:memcached模块间的关联性太多了。
item *do_item_alloc(char *key, const size_t nkey, const int flags,
const rel_time_t exptime, const int nbytes,
const uint32_t cur_hv) {
uint8_t nsuffix;
item *it = NULL;
char suffix[40];
//要存储这个item需要的总空间
size_t ntotal = item_make_header(nkey + 1, flags, nbytes, suffix, &nsuffix);
if (settings.use_cas) {
ntotal += sizeof(uint64_t);
}
//根据大小判断从属于哪一个slab
unsigned int id = slabs_clsid(ntotal);
int tries = 5;
item *search;
item *next_it;
rel_time_t oldest_live = settings.oldest_live;
search = tails[id];
for (; tries > 0 && search != NULL; tries--, search=next_it) {
next_it = search->prev;
uint32_t hv = hash(ITEM_key(search), search->nkey);
/* Now see if the item is refcount locked */
if (refcount_incr(&search->refcount) != 2) {//援用数>=3
refcount_decr(&search->refcount);
continue;
}
//search指向的item的refcount等于2,这说明此时这个item除本worker
//线程外,没有其他任何worker线程索引其。可以放心释放并重用这个item
//由于这个循环是从lru链表的后面开始遍历的。所以1开始search就指向
//了最不经常使用的item,如果这个item都没有过期。那末其他的比其更经常使用
//的item就不要删除(即便它们过期了)。此时只能向slabs申请内存
if ((search->exptime != 0 && search->exptime < current_time)
|| (search->time <= oldest_live && oldest_live <= current_time)) {
..
} else if ((it = slabs_alloc(ntotal, id)) == NULL) {//申请内存失败
//此刻,过期失效的item没有找到,申请内存又失败了。看来只能使用
//LRU淘汰1个item(即便这个item并没有过期失效)
if (settings.evict_to_free == 0) {//设置了不进行LRU淘汰item
//此时只能向客户端回复毛病了
itemstats[id].outofmemory++;
} else {
//即便1个item的exptime成员设置为永不超时(0),还是会被踢的
it = search;
//重新计算1下这个slabclass_t分配出去的内存大小
//直接霸占旧的item就需要重新计算
slabs_adjust_mem_requested(it->slabs_clsid, ITEM_ntotal(it), ntotal);
do_item_unlink_nolock(it, hv);//从哈希表和lru链表中删除
/* Initialize the item block: */
it->slabs_clsid = 0;
}
}
//援用计数减1。此时该item已没有任何worker线程索引其,并且哈希表也
//不再索引其
refcount_decr(&search->refcount);
break;
}
...
return it;
}