日志收集系统Flume调研笔记第1篇 - Flume简介
1. Flume是甚么
2. Flume的适用处景
3. Flume典型系统架构
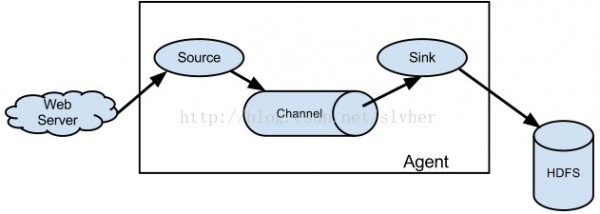
3.1 Source
Source负责接收并解析(如反序列化)来自外部源的events数据,并将解析后的数据发送给与它连接的1个或多个channel(s)。
几点说明以下:
1) 外部源发往Source的数据格式必须与Flume配置文件中指定的Source Type保持1致。比如,若配置Flume的Source类型为thrift,则发来的数据必须按thrift协议打包。
2) 目前Source支持的接收外部源数据的方式包括RPC(如将Source配置为Avro方式时,可通过Avro客户端以RPC方式向Flume发送数据)、Thrift源、HTTP源、Exec源、JMS源、Seq源(类似于计数生成器,它会延续生成event,主要用于测试),等等。具体支持的Source列表及使用实例,可参考官方文档Flume
Sources的说明。
3) 在同1个agent进程中,若source配置了多个channels,此时,根据业务需求,可为source配置不同的event路由策略,常见的channel selector包括replicating和multiplexing两种,其中,前者为默许策略,表示来自source的events会同时发往与它连接的所有channels(明显这类情况会更耗内存或磁盘);而后者表示source的events只会发送到特定的channel(s),具体而言,source通过其配置项selector.header指定路由决策字段的key,通过配置项selector.mapping.<hdr-value>指定与hdr-value匹配的events将要发往的channel,其中,<hdr-value>是与决策字段的key关联的value。具体实例可参考Flume
Channel Selectors文档的说明。
4) 可以借助source. Interceptors修改或过滤event,细节可参考文档Flume Interceptors。
5) 自定义实现的Source也能够作为plugin集成到Flume中。
3.2 Channel
Channel是个被动的存储组件,它会保护1个内存队列或磁盘文件来保存Source发来的event直到该event被Sink消费。也即,它像队列1样连接了sources和sinks。
最多见的Channel类型是Memory Channel和File Channel,前者通过在内存队列中保护events来提高性能,但机器故障或进程退出时会丢失未被Sink消费的数据;而后者通过磁盘文件保护events,可以免意外情况情况下的数据丢失,但明显性能会打折扣。
除Memory Channel和File Channel外,Flume还支持JBDC Channel及其它的Channel类型,细节可以查看Flume Channels文档。
几点说明以下:
1) 在使用memory类型的channel时,要意想到最大容量(capacity)问题,如果source生产events的速度超过sink的消费速度,则可能会致使channel缓冲区打满从而抛出异常。这类情况下,若向Source写数据的外部利用程序没有异常处理逻辑(ExecSource最容易出现这类情况),则数据会丢失。
2) 在使用file类型的channel并配置了多个file channels时,最好为每一个channel明确配置寄存events的、各自独立的文件路径,由于若采取默许的配置路径,则多个channel会竞争同1个文件锁,终究致使只有1个channel能初始化成功。
3) 可以配置memory和file混合的channel类型Spillable Memory Channel,优缺点可以查看文档,这里不赘述。
4) 自定义实现的Channel接口可以作为plugin集成到Flume中。
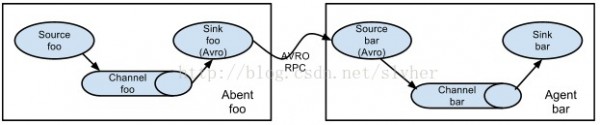
4. Flume级联
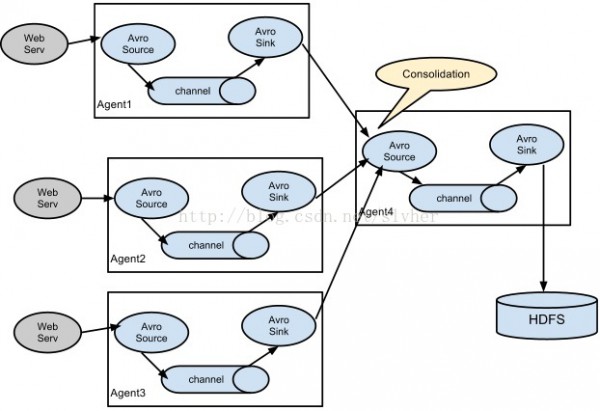
2) 多agent聚合级联
3) 多路分流
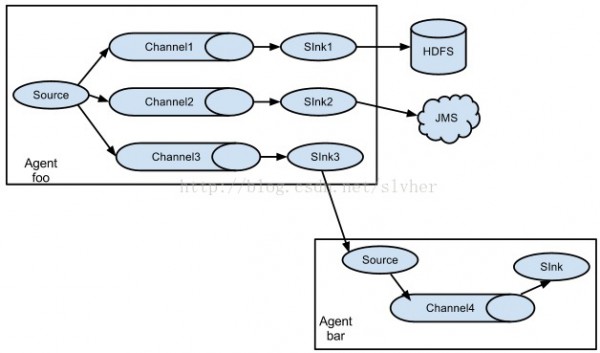
上图中,source的events可以根据配置分配到不同的channel中,这类方法在上文介绍source的要点说明中曾描写过,这里不再赘述。
3. Flume1.5.2 User Guide - Is Flume a good fit for your problem?
4. Flume NG PerformanceMeasurements
5. Apache Flume - Architecture of Flume NG