网页抓取与处理的一些方法
栏目:htmlcss时间:2015-01-06 08:43:06
昨天还是2014,今天就变成了2015。时间总是那末快,这篇文章就作为2015年的1个开始吧。
这篇文章主要介绍1些网页抓取及抓取下来的内容处理。
所需要的jar包点击打开链接,我放在百度云盘里。有需要的可以下载,其他的请自行下载。
百度百科对网页抓取的定义,固然本文并没有介绍的那末多,只是介绍对单个页面的抓取,和摹拟提交表单抓取页面,如需深究,请自行baidu or google。
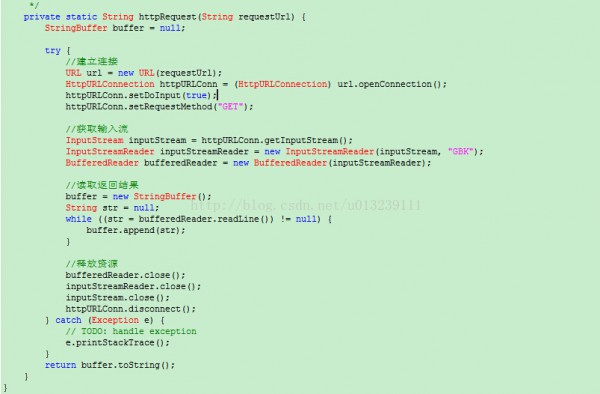
上面的方法直接返回String字符串,只需传入1个链接便可。相信大家都看的懂。
那末获得到的String字符串,我们该怎样处理呢?
我先拿1个网站测试下。就比如这个点击打开链接,这个网站显示了今天在历史上产生了甚么大事件。而我们要抓取的内容只有1部份,比如:历史上今天大事记


或历史上今天去世

这里就对抓取历史上今天大事记做1个介绍。

这里用到了1个extract的方法,也就是对www.rijiben.com获得的的String字符串进行分割,获得到我们需要的信息。

这里的html也就是上面传进去的html。compile里面是正则表达式,它把全部页面分成了5段,那末我们应当如何获得到里面的那1段呢?

group里面的数字就是获得分割后的哪1段。
具体的可以查看这里。
下面介绍如何摹拟提交表单后抓取页面,其实原理与上面大同小异。
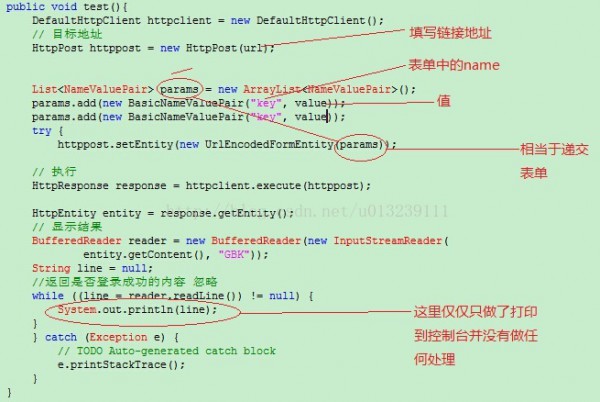
相信我上面的图片已很明显的把功能都说明了,后续对表单提交后显示的页面做其他处理就要看你怎样做了 。
。
最后祝大家元旦快乐
------分隔线----------------------------
------分隔线----------------------------