scrapy_redis只能使用redis的db0?
背景:
尽人皆知,Redis默许的配置会生成db0~db15共16个db,切分出16个db的1个作用是方便不同项目使用不同的db,避免的数据混淆,也为了方便数据查看。
Python在连接Redis时如果没有指定用哪个db则默许使用db0。使用过scrapy_redis模块的同学也知道去重和种子队列都在db0上。
现在有1个基于scrapy、Redis的散布式爬虫,是从同事那边接手过来的。本来没觉得scrapy_redis使用db2来寄存request和dupefilter有甚么难度,也就没在乎他的代码是怎样实现的了,只知道他的爬虫将种子和去重都放在了db2。昨天添加功能改代码,将代码从服务器拷贝出来跑测试,发现数据是寄存在db0中的。仔细看了代码,没发现哪里改成了db2,但服务器上跑为何会把数据存到db2呢?1样的代码,保存的地方居然不1样?大惑!
半信半疑地去看了1下服务器中scrapy_redis的源码,发现connection.py中连Redis的代码居然被改了!
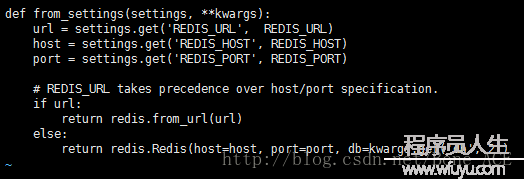
也是有点醉!直接改python模块的源代码是大忌!虽然这样改简单快捷,但是模块是公用的代码,如果其他项目也要用到这个项目的话就乱了,而且也不利于本项目代码的迁移,与饮鸩止渴无差。
然后看了scrapy_redis模块的源码,发现scrapy_redis在连接Redis时并没有指定db,默许db0。并没有接口让用户指定db。那末问题来了,scrapy_redis想要使用redis的db2,该怎样做?
解决:
1、同事那个改法就很简单快捷(如上方图片),但是不能直接改模块源码,要把源码复制1份出来,放在项目目录下,然落后行修改。项目调用scrapy_redis时也是调用本目录下的scrapy_redis。
2、第2种是用继承。见上方的图片,代码的作用是实例化生成1个redis连接对象,1般情况下是返回redis.Redis()对象。这个方法被scheduler.py下的from_settings()方法调用。代码以下:

我们可以继承这个方法,再来个移花接木。
具体方法:在settings.py同级目录下新建1个文件schedulerOverwrite.py,填入下面的代码。然后在settings.py设置SCHEDULER=schedulerOverwrite.SchedulerSon,以后在settings.py中设置REDIS_DB=XXX便可指定db。
import redis
from scrapy_redis.scheduler import Scheduler
from scrapy.utils.misc import load_object
# default values
SCHEDULER_PERSIST = False
QUEUE_KEY = '%(spider)s:requests'
QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
DUPEFILTER_KEY = '%(spider)s:dupefilter'
IDLE_BEFORE_CLOSE = 0
REDIS_URL = None
REDIS_HOST = 'localhost'
REDIS_PORT = 6379
REDIS_DB = 0
def from_settings(settings):
url = settings.get('REDIS_URL', REDIS_URL)
host = settings.get('REDIS_HOST', REDIS_HOST)
port = settings.get('REDIS_PORT', REDIS_PORT)
db = settings.get('REDIS_DB', REDIS_DB)
# REDIS_URL takes precedence over host/port specification.
if url:
return redis.from_url(url)
else:
return redis.Redis(host=host, port=port, db=db)
class SchedulerSon(Scheduler):
@classmethod
def from_settings(cls, settings):
persist = settings.get('SCHEDULER_PERSIST', SCHEDULER_PERSIST)
queue_key = settings.get('SCHEDULER_QUEUE_KEY', QUEUE_KEY)
queue_cls = load_object(settings.get('SCHEDULER_QUEUE_CLASS', QUEUE_CLASS))
dupefilter_key = settings.get('DUPEFILTER_KEY', DUPEFILTER_KEY)
idle_before_close = settings.get('SCHEDULER_IDLE_BEFORE_CLOSE', IDLE_BEFORE_CLOSE)
server = from_settings(settings)
return cls(server, persist, queue_key, queue_cls, dupefilter_key, idle_before_close)
转载请注明出处,谢谢!(原文链接:http://blog.csdn.net/bone_ace/article/details/54139500)
下一篇 git tag