【HDFS】HDFS的整体架构设计,阅读笔记
栏目:互联网时间:2015-03-23 08:10:51
HDFS是1个高度容错性的系统,合适部署在便宜的机器上。
HDFS可能由成百上千的服务器构成,每一个服务器上存储着文件系统的部份数据,构成系统的组件数目是巨大的,任1组件都有可能失效,这意味着总是有1部份HDFS的组件是不工作的,所以HDFS的核心架构目标是毛病检测和快速、自动的恢复。
HDFS上的1个典型文件大小1般都在G字节至T字节
1个单1的HDFS实例应当能支持数以千万计的文件
HDFS利用需要1个“1次写入屡次读取”的文件访问模型。1个文件经过创建、写入和关闭以后就不需要改变。这1假定简化了数据1致性问题,并且使高吞吐量的数据访问成为可能。
1个利用要求的计算,离它操作的数据越近就越高效,在数据到达海量级别的时候更是如此。
HDFS为利用提供了将它们自己移动到数据附近的接口。
架构
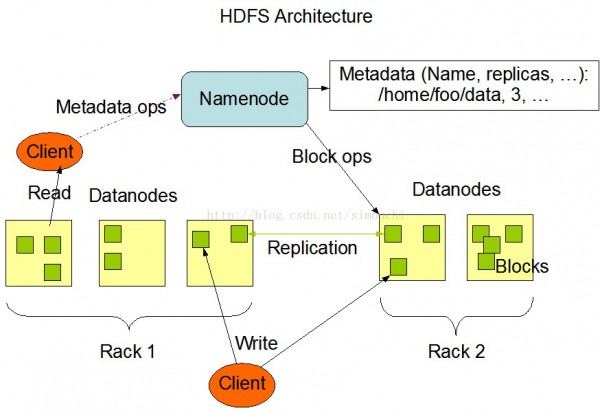
HDFS采取主从架构,1个HDFS集群有1个namenode和1定数目的datanode组成。
namenode是1个中心服务器,负责管理文件系统的名字空间(namespace)和客户端对文件的访问(namenode去映照文件所在datanode)。
集群中的datanode1般是1个节点作为1个datanode,负责管理自己节点上的存储。
1个文件被分成1个或多个数据块,存储在1组datanode上。
namenode负责履行文件系统操作,肯定数据块到具体datanode节点的映照。
datanode负责处理文件系统客户真个读写要求,在namenode的统1调度下进行数据块的创建、删除、复制。
HDFS采取JAVA开发,因此任何支持java的机器都可以部署namenode和datanode
集群中单1Namenode的结构大大简化了系统的架构。Namenode是所有HDFS元数据的仲裁者和管理者,这样,用户数据永久不会流过Namenode。
HDFS被设计成能够在1个大集群中跨机器可靠地存储超大文件。它将每一个文件存储成1系列的数据块,除最后1个,所有的数据块都是一样大小的。为了容错,文件的所有数据块都会有副本。每一个文件的数据块大小和副本系数都是可配置的。利用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也能够在以后改变。HDFS中的文件都是1次性写入的,并且严格要求在任什么时候候只能有1个写入者。
Namenode全权管理数据块的复制,它周期性地从集群中的每一个Datanode接收心跳信号和块状态报告(Blockreport)。接收到心跳信号意味着该Datanode节点工作正常。块状态报告包括了1个该Datanode上所有数据块的列表。
HDFS采取1种称为机架感知(rack-aware)的策略来改进数据的可靠性、可用性和网络带宽的利用率。
通过1个机架感知的进程,Namenode可以肯定每一个Datanode所属的机架id。1个简单但没有优化的策略就是将副本寄存在不同的机架上。这样可以有效避免当全部机架失效时数据的丢失,并且允许读数据的时候充分利用多个机架的带宽。这类策略设置可以将副本均匀散布在集群中,有益于当组件失效情况下的负载均衡。但是,由于这类策略的1个写操作需要传输数据块到多个机架,这增加了写的代价。
在大多数情况下,副本系数是3,HDFS的寄存策略是将1个副本寄存在本地机架的节点上,1个副本放在同1机架的另外一个节点上,最后1个副本放在不同机架的节点上。这类策略减少了机架间的数据传输,这就提高了写操作的效力。机架的毛病远远比节点的毛病少,所以这个策略不会影响到数据的可靠性和可用性。于此同时,由于数据块只放在两个(不是3个)不同的机架上,所以此策略减少了读取数据时需要的网络传输总带宽。在这类策略下,副本其实不是均匀散布在不同的机架上。3分之1的副本在1个节点上,3分之2的副本在1个机架上,其他副本均匀散布在剩下的机架中,这1策略在不侵害数据可靠性和读取性能的情况下改进了写的性能。
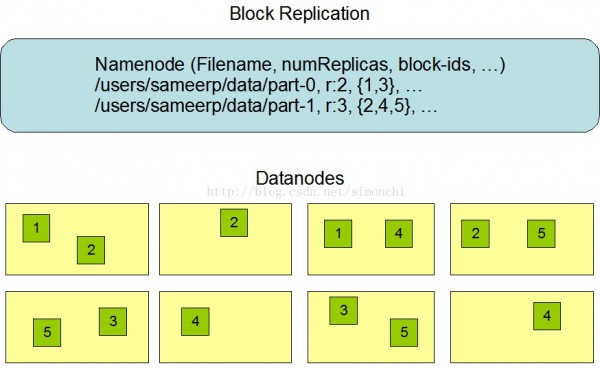
HDFS会尽可能让读取程序读取离它最近的副本
namenode启动后会进入1个安全模式的特殊状态,这时候候不会进行块复制,但是会通过块状态报告确认是不是安全(数据块副本到达最小值的比例),安全后则退出,后续会肯定哪些块副本未达标的将进行块复制。
EditLog事务日志,FsImage文件块映照、文件属性等
namenode在内存中保存映照表,这个数据结构设计紧凑,4G内存的namenode足够支持大量的文件和目录;
当namenode启动时,从硬盘读取EditLog和FsImage,将所有的EditLog中的事务作用在内存的FsImage上,并将新的FsImage从内存保存到磁盘上,然后删除旧的EditLog,这就是检查点进程。
如果namenode很久都没有启动,那末EditLog是否是渐渐变的愈来愈大了(由于只有启动才会合并fsimage和edits),下1次启动很慢!!
所以secondary namenode就应运而生了,负责定期合并fsimage和edits,将edits日志大小控制在1个限度下。和namenode在不同机器上

datanode启动时,扫描本地文件系统,产生1个本地文件对应的所有HDFS数据块的列表,将这块状态报告发送给namenode。
FsImage和Editlog是HDFS的核心数据结构。如果这些文件破坏了,全部HDFS实例都将失效。
因此,Namenode可以配置成支持保护多个FsImage和Editlog的副本。任何对FsImage或Editlog的修改,都将同步到它们的副本上。这类多副本的同步操作可能会下降Namenode每秒处理的名字空间事务数量。但是这个代价是可以接受的,由于即便HDFS的利用是数据密集的,它们也非元数据密集的。当Namenode重启的时候,它会选取最近的完全的FsImage和Editlog来使用。
网络毛病的解决,datanode失效??
每一个datanode节点周期性的想namenode发送心跳信号。网络断开可能致使1部份datanode和namenode失去联系,namenode通过心跳信号的缺失将此datanode标记为宕机,不会在将新的IO要求发给它们。这进1步致使1些数据块的副本系数降落,namenode会不断检测需要复制的块并启动复制操作。
DFSAdmin
hadoop is deprecated,use hdfs

如何知道谁是admin呢??
启动NameNode的用户被视为HDFS的超级用户
副本系数减小
namenode感知到会将过剩的副本删除,下个心跳会将该信息传递给datanode,datanode行将数据块删除,空闲空间加大。
fsck用来检查文件系统
用法:hadoop fsck [GENERIC_OPTIONS]
<path> [-move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]]

------分隔线----------------------------
上一篇 剪枝算法(算法优化)
下一篇 备孕、怀孕、产子、月子知识大全
------分隔线----------------------------