DIY“物联网”――自己动手处理传感器数据
【编者按】传感器已经大量部署于实际生产中,涉及航空、电力、医疗、教育各个行业的传感器形成大规模的工业物联网,各式各样的传感器产生了大量的数据,如何去分析这些数据,作者用Raspberry Pi和四个Tinkerforge传感器DIY了一个办公室“物联网”,模拟了现实生产中传感器应用,为我们带来了一些有益的借鉴,下面是作者的精彩分析。
以下为译文:
当前的一个客户项目和一般工业大数据项目的有趣性质(数据产生于传感器)给了我启发,我决定自己动手处理传感器数据,我想通过这个小实验,了解具体如何处理、存储和分析这些数据,以及在这一过程中会遇到哪些挑战?
为了获取传感器数据,我们决定把传感器安装到我们的办公室里,生成我们自己的传感器数据,我们发现Tinkerforge的bricks和bricklets系统非常友好,易于上手,于是我们选择采用Tinkerforge系统。
我们得到了以下四个传感器bricklet:
- 声音强度传感器(实际上是个小麦克风)
- 温度传感器
- 多点触摸bricklet(12个自制的可连接铝箔垫)
- 运动探测器
四个bricklet都连接到主bricklet上,然后将主bricklet连接到Raspberry Pi。
我们把温度传感器放在办公室的中央,将运动探测器安装在厨房和浴室之间的走廊里,把声音强度传感器放在厨房门边,而触摸传感器则放在咖啡机、冰箱门和厕所的门把上。
虽然这样的设备很难跟实际生产中的情形相比(而且为了获取足够多的数据,你需要等很长时间),在这次小小的实验中,我们还是很快遇到了那些现实传感器应用过程中的一些关键问题。
我们选择了MongoDB作为存储解决方案,主要是因为我们的那个客户项目也使用了MongoDB。
四个传感器产生的数据可以分为两类:温度和声音强度传感器输出连续的数据流,运动探测器和多点触摸传感器往往是由非固定频率的事件触发。
这就形成了MongoDB中两种不同的文档模式。对于第一类(流),我们使用MongoDB推荐的模式,实际上也是这种情况下的最佳实践,即“时间序列模式”(见 http://blog.mongodb.org/post/65517193370/schema-design-for-time-series-data-in-mongodb),由一个内部的嵌套文档集合组成。嵌套的层数和每个级别子文档的数量取决于数据的时间粒度。在我们的实验中,Tinkerforge传感器的最高时间分辨率为100ms,产生了下面的文档结构:
- 每小时一篇文档
- 字段:小时时间戳、传感器类型、值
- 值:嵌套的子文档(subdocument)集,每分钟60个子文档(subdocument),每一秒60个子文档(subdoc),每1/10秒10个子文档(subdoc)

MongoDB中文档是预先分配的,预先对所有的字段进行初始化,保证初始值大于传感器的数据范围,这样做是为了避免由于MongoDB数据库中文档持续增多造成的麻烦。
第二个类型的数据(事件驱动/触发)以类“bucket”文档模式存储。针对每个传感器的类型,需要预先为值分配固定数量的条目(一bucket分配100个)。当事件发生时,将其写入这些文件中,每个事件对应100个条目组的一个子文档,子文档贯穿着事件的始终。当记录/事件第一次被写入到文档中时,全部文件获取与开始日期对应的时间戳。每次写入到数据库时,应用程序都会检查当前记录是否已经写入到当前文档,如果写入已经完成,它会设置文档的结束日期/时间并启动引导到下一文档的写入。

这两个文档模式表示权衡的边界情况,在传感器数据中比较常见。
MongoDB推荐的“时间序列”模式很适合高效写入,而且兼具良好、一致性架构的优势:每个文档都对应着一个时间单位(在我们的实验中,时间单位为一个小时),这使得管理和检索数据非常方便。此外,还可以很容易从当前的时间推断出要写入的“当前”文档,所以应用程序不需要一直对文档进行追踪。
嵌套结构实现了对不同粒度级数据的整合――虽然应用中这些整合不得不手动执行。由于这样一个事实,在该文档模式中,“分钟”、“秒”和“毫秒”不再有单一的键,相反,每一分钟、 每一秒、每一毫秒都有各自的键。
一旦数据变得稀疏、不连续,这个模式就会出现问题。实验中,这些数据显然是由运动探测器和多点触摸传感器产生:由于事件是随机发生的,所以数据也没有固定的频率。对于时间序列文档模式,这就意味着文档的某些字段永远用不到,这显然是对磁盘空间的一种浪费。
如果传感器数据开始时不是通过事件驱动的话,也会产生稀疏数据。换句话说,许多传感器,虽然它们以一个固定的频率测量数据,但是只会自动输出相对于上一次测量改变的值,这个问题已经被解决了,如果你想要坚持时间序列文档模式,就需要经常检查是否有值被传感器省去,以传感器发出的最新值更新数据库。当然,这有可能会在数据库中引入大量的冗余。
Bucket模式中用实际已记录的数据填充文档,避免了这一问题,但它也有自身的缺点:
- 应用程序需要处理有可能出现的全部数据重建问题(包括尚未保存的冗余数据)
- “bucket”文件没有一致的开始和结束时间――如果你对特定时间范围感兴趣,你就必须查找该范围内的所有文件
- “bucket”的管理(跟踪当前的bucket,检查bucket是否为满)需要应用程序解决
Tinkerforge传感器带有多语言版本的API,我们决定使用Python,在连接传感器的Raspberry Pi上运行脚本,数据则写入到MongoSoup托管的MongoDB实例中,MongoSoup是我们的MongoDB即服务解决方案。通过API注册例如声音强度和温度bricklet,你需要执行下列操作:
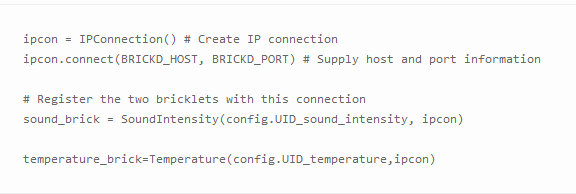
Tinkerforge API支持通过回调函数从传感器中自动地读取数据。若要使用此功能,你需要注册你想要通过bricklet触发的功能:
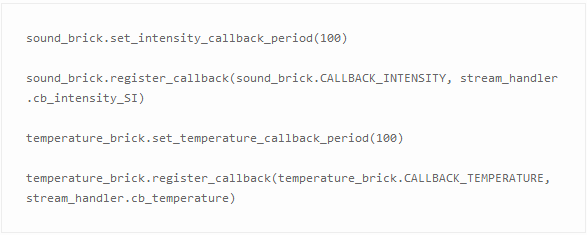
它将以每100ms的速度自动查询传感器的新数据并分别调用stream_handler.cb_intensity_SI和stream_handler.cb_temperature函数。
为了节省网络带宽,只在上一次传感器的测量值发生改变时,你提供的功能才会被触发――也产生了上文讨论的稀疏数据。
可以通过直接自定义代码的方式,以一个固定的频率查询传感器来避免这种现象。但是,就如上文所说的那样,这会导致数据库中充满了冗余数据。此外,它增加了从传感器到应用程序的网络开销。
最后,其中一个将必须决定哪种模式更适合用例。关于数据模式,MongoDB提供了大量元数据模式,你的选择应完全由用例(比如你最有可能遇到的读/写模式)来决定。
一个好方法是在决定一个文档模型之前,问以下几个问题:
- 从整体的角度考虑(考虑到帐户数据库和应用程序性能),是数据库中的稀疏/冗余代价高?还是之后重建应用程序中的冗余数据代价高?
- 数据实际上有多大变化?如果周期性的持续测量比较少,那最好留有一定量的冗余。
- 从一个更大的时间尺度看,有恒定的频率吗?例如,你的数据主要是以几秒钟为周期的分段常数,而这些周期的长度相同,那你可能需要考虑粗粒化时间尺度,丢掉小尺度内的冗余信息。
- 假如出现另一种情况,常数的长度变化太快,事件随机发生,那你最好还是选择用bucket模式。
在我们的实验中,最初的假设是温度数据和声音强度数据会有很大变化,我们需要将它们存储在“时间序列”数据模式中,而运动探测器和触摸传感器数据适合用bucket模式,实际上我们也是这么做的。
在完成安装并执行处理传感器数据的Python脚本后,我们开始收集数据。
我们使用matplotlib和Flask web服务器框架,搭建起一个小型的web服务,直观显示最近收集的数据以用于检查,并将该web服务部署到Heroku。
我们生成三个plot,第一个随着时间变化分别显示触摸传感器和运动探测器的事件,其他两个显示随着时间的推移声音强度和温度水平,plot中的每个数据点平均一秒钟计算一次。
一眼就能看出办公室中人员活动产生的不同传感器数据之间存在明显相关性。
你可以确定选择使用bucket模型是正确的,因为经常会有在长达20 分钟的时间里,传感器没有记录下任何东西。
看一下温度数据,虽然它会有波动,但很明显这种波动保持在1摄氏度的范围内。如果用例是监测全球白天温度的变化,那很可能需要在时间上采用粗粒度数据写入或者切换到bucket模式。
声音强度数据表现为:长时间的安静(测量值很小)之后大声事件突然、短时间爆发。这样短时间的数据肯定不容许被遗漏,所以上述的粗粒度办法行不通,不过可以考虑切换到bucket模型,仅向数据库中写入变化的数据测量值。
原文链接:Processing and analysing sensor data