精英团队PK全能型数据科学家,拼的可不只是数量
【编者按】作者Gil Press是Forbes的专栏作家, 本文他借用Kdnuggets网站的一次投票,为我们分析了大数据时代解决企业数据人才匮乏的方案。是要一个全能型的数据科学家?还是组建一个数据团队?或者使用数据分析软件?不同的人站在不同的角度肯定会有不同的看法,作者似乎更倾向于利用团队的力量,一个由不同学科人才组成的管理完善的团队也无疑是个很好的方案,看作者本人如何分析。
CSDN推荐:欢迎免费订阅《Hadoop与大数据周刊》获取更多Hadoop技术文献、大数据技术分析、企业实战经验,生态圈发展趋势。
以下为译文:
Gregory Piatetsky最近在他颇受欢迎的Kdnuggets网站上进行了一次 民意调查,让读者们投票选择在组织中建立数据科学能力的最优方法。这次投票是对Michael Mout 帖子有力地回应。Michael Mout劝说雇主不要招聘全能的“数据科学家”, 只聘用计算机科学家、统计学家和数据库管理员,然后将他们组成一个数据科学团队。
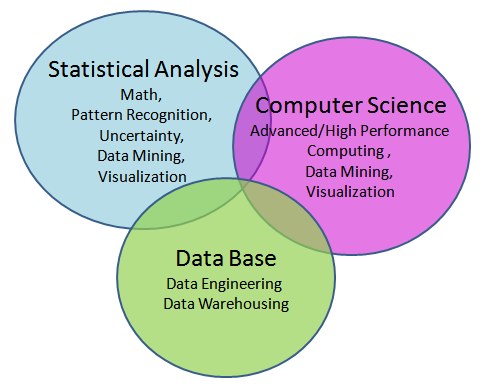
一位资深统计学家认为“数据科学”通常包含3个领域,这3个领域的技能、教育和训练有很大不同,很少重叠。
Piatetsky的受访者同样被分成了势力相当的两派,一些人倾向于“寻找和培养具备所有(或大部分)所需技能的全能型数据科学家”,另一部分人则选择“建立一个数据科学团队,每个成员专注于某一项技能”。一些倾向于“个人”的受访者考虑到资源有限的小公司。对于“个人”,更具实质性的争论是:专家并不一定是全能的。

在任何专业领域做到全能都是难能可贵的,但如果指数据科学处理中所需技能的多样性,特别是当你考虑Mont提到的那些附加技能,那这或许仅仅是一种才华的展现了。在 HBR博客上,Brad Brown和Brian Henstorf建议用“技术与数据专家”、“分析师与数据科学家”以及“业务分析与解决方案专家”组成一个数据科学团队。同样,Dawen Peng在 Think Operations Research博客上也列出了以下技能:业务咨询、分析与建模、通信与可视化、数据工程,还有编程。
这个关于数据科学家的辩论:是具有多个技能和实践经验的全能型个人好,还是多学科团队更优?这其实和被认可数据科学家的稀缺有关。我之所以强调是“被认可的”,是因为数据专家本身就是个模糊的概念,不可能估计出(即使对于数据科学家来说也一样)数据专家的供需情况。
2011年McKinsey全球研究所对大数据的一份报告,经常被引用作为数据科学家不足的权威资料,实际上这份报道是关于美国面临的“14万到19万具备深入分析技能人才的短缺”。即使你假设用具备“深入分析技能”(McKinsey把它定义为“在统计或机器学习方面接受高等教育的人”)来定义数据科学家(McKinsey没有使用这个词)已经足够了,你应该把报告和相关的附录完整地读完,去了解McKinsey的定义和假设(例如“到2018年整个经济领域的公司完全采用大数据技术”),还有基于假设得到供需不平衡的这种看似准确的预测。
McKinsey公司第一次公开对大数据综合评估,试图预测大数据在未来的重要潜力,这一点还是值得称赞的,而且最重要的是,它用数字告诉我们大数据时代的到来。但对于数据科学家未充分利用和短缺问题没有采取任何行动、不论在现在还是将来,这都是不争的事实。
我申明我只是指出基于研究报告错误引用的炒作成为了“事实”(必须承认McKinsey的执行摘要可能有更详细的内容而且更严谨,但我猜“执行”这两个字换成“买方须知”也差不多吧)。我毫不怀疑在我们数据饱和的世界,对具有“深分析技能”人的需求,已经持续相当长的一段时间了,North Carolina州业务分析项目专业的就业成功率证明了这一点。这个特殊的项目――2012年的所有84个毕业生都找到了工作――这个项目成立于2007年,距离我们被告知大数据时代缺乏数据科学家还很早。不管过去的“深分析技能”从哪个教学计划毕业――业务分析、运筹学、统计学,或任何其他学科(或工作经验),都培养了他们的数据挖掘技能――他们都很快找到了工作,假如他们对数据分析工具(60年代发展起来的SAS和SPSS)有实际操作经验的话,可能会更有优势。
“数据科学家”,新的定义是“具有深入数据分析能力的人”――和供求失衡的事实相联系――是由新的教育项目推动的,用供应商的新工具自动管理和挖掘不断增长的数据,取代了“业务分析”和“数据科学”。供应商,尤其是那些注重精简或使数据分析过程自动化的供应商,理所当然有兴趣把个人vs.团队的问题转移到一个结论,那就是不管哪种方案都是不可行的,因为你找不到数据科学家,最好的办法就是用工具使他们的工作或部分工作自动化。
这真是令人耳目一新,后来读到了Joe Hellerstein(Trifacta的合伙人,Trifacta试图使数据清洗、艰苦和枯燥的数据分析过程实现自动化),必须要谈一下数据科学了:“任何承诺在数据分析领域实现自动化的人都陷入了毫无意义的自大。数据分析是一个过程,从根本上说是关于人的过程(能够理解业务问题和有关数据之间联系,建立假说并解释最终的数字的人),不仅仅是技术。说到底,数据科学――像所有的科学一样――是人类的创造性活动。拿走‘科学’,就只剩下‘数据’了。”
Hellerstein认为解决被他称为“三重技能数据科学家”稀缺的办法是利用人为分析协同工作的技术,使数据科学更有成效、适用面更广。他同意将有不同技能的人组成团队是一个“明智的办法”,但很多组织以“成本太高”、“市场中精通某项技术的人也很少,没有可行性”等理由将团队解散,在捍卫对人才的需求的同时,他支持使用工具来实现自动化,至少简化数据科学家的部分工作。
福特的数据科学家Caveretta很难同意这样的观点:“虽然有很多的供应商说,‘你不需要数据科学家,只要用我们的软件就行了,’......要实现用软件取代数据科学家,还需要很长时间。”他选择团队方案:“你不需要找这些“独角兽”们,这些人很难找到,你还得付给他们难以置信数额的钱。你可以建立一个能完成数据分析的团队,对我来说这已经足够了,和我们引进数据科学家一样,在公司内部建立数据分析团队同样具有战略意义,用公司内部人才补充数据科学家这一空缺是个不错的方案。”
大约五年前,Linkedin网站定义了数据科学家这一角色,DJ Patil也选择 采取团队办法,但规模更大,团队中还包括了与编程和统计无关的人:“我们的数据团队不能只是由纯粹的数学家和其他和数据相关的人组成,这一点很重要。它是一种完全集成的生产组,包括设计、web开发、管理、产品营销和运维各个领域的人。他们都理解数据而且工作中也接触到数据,我认为他们都是数据科学家。我们刻意模糊组织中不同的角色之间的界限。
在我看来,这正是团队的力量,这也解释了为什么要用团队方案,即使是在我们有充足的数据科学家或“有深入分析能力的人”(不管怎么称呼他们)的情况下。相比个人或同类型技能和经验的人组成的团队,由具有不同技能和经验的成员组成的团队有可能做出更好的决策。这不只是因为基于不同经验和专业知识不同观点有助于更好地了解不同情况和行动的潜在后果。管理良好的团队鼓励辩论,不同的观点有助于减少或消除团队成员的个人偏见。
这让我想起了在之前的文章中讨论过的McAfee定律:“随着数据量的上涨,人为判断的重要性应该下降。也许应该这么说:随着数据量的上涨,管理完善、高度跨学科团队的人为判断比以往任何时候都更为重要。
原文链接:
Big Data Debates: Individuals Vs. Teams(编译/毛梦琪 审校/魏伟)
上一篇 杨煜尧:当科研项目遇上AWS云