走进支撑过8亿用户的Yahoo!数据中心
【编者按】Yahoo!是一家全球知名的互联网公司,拥有过8亿的活跃用户,提供了60多个全球化产品,分别部署在20多个国家或地区的数十万台服务器之上,然而雅虎全球的运维团队却仅有数百人。下面,我们通过雅虎北京全球研发中心高级系统运维工程师刘元概述的三个方面来了解雅虎的技术运维体系,剖析超大规模网络应用的运维挑战,走进Yahoo!数据中心!以下为原文:
基础设施
“工欲善其事,必先利其器”――需要支撑超大规模的网络应用,超大规模的全球基础设施是必不可少的。所以我们先看Yahoo!数据中心和全球的骨干网络有哪些特别的设计和考虑,来帮支撑超大规模的互联网应用。


图1 Yahoo自主设计的数据中心
首先通过两张图片(图1)来了解Yahoo!数据中心。我们的数据中心大多是自主设计和建造的,尤其在北美地区,我们自主设计并建造了三个超大规模的数据中心。这三个数据中心初期设计的容量均为20兆瓦,大概可容纳25000到30000台服务器及相应网络设备,并均有能力通过后续容量扩展至50兆瓦以上。
如果有参观过国内数据中心,或者有数据中心建设经验的同学可能会有所了解。影响数据中心建设的最主要因素往往不是网络带宽,而是电力和制冷。所以,雅虎通过近20年的经验积累,在这两方面沉淀了大量的专利技术以提高数据中心的密集度。我们自行设计机架及其电源模块以保证所有机架都能满负荷工作,同时实现所有电源的远程网络控制,这样可以有效的提升可维护性,降低现场工程师的工作负担。满架的服务器机架还有另一个好处:所有的服务器都是前吸冷风,后排热风,我们将服务器机架相对排列(面对面,背对背),这样就可以实现冷热风道的隔离,甚至完全密封热风通道,促使冷空气在均匀通过所有服务器散热后,由热风通道排出。这样不仅降低了制冷面积,还提升了散热效率。通过建设超大规模的数据中心,我们不仅增加了数据中心的密集度,提升了单个数据中心的计算能力,满足了日益增长的超大规模应用需求,同时还能提升数据中心现场工程师的管理效率,降低维护成本。此外,我们也不断聚焦新技术的采用以降低能源消耗。我们数据中心通过精心的设计,实现PUE(能源使用效率=总体能源消耗/IT设备能源消耗,越接近1代表能源效率越高)仅为1.08的业界领先水平。
除了数据中心是我们自行设计并建造的,我们全球的骨干网络也是自主设计。我们通过自行铺设光缆或租用运营商网络,构建了自己的Yahoo!全球骨干网。所有的网络设备都由我们的网络运维团队管理,核心网络均是多链路冗余,实现单点网络故障的自动转移,而不依赖网络运营商提供的SLA。
图2全球骨干网络示意图(不代表Yahoo!全球骨干网络设计)
我们的全球骨干网络均为高带宽互联,区域内我们提供10Gbps-40Gbps乃至北美地区的200Gbps互联带宽,洲际间也提供20Gbps的多链路冗余。骨干网络主要是传输雅虎内部数据,分发应用所需的数据到全球所有数据中心,收集全球用户访问数据到后端计算网格进行汇总和计算。
Yahoo!全球骨干网络除了与传统运营商网络互联互通,以方便最终用户能通过其运营商网络快速接入雅虎的各项服务,同时我们还与其他的大型互联网公司有交换网络连接,这样我们与其他大型互联网公司间的数据交换(如邮件数据交换)即可通过我们的交换网络传输,不再依赖于运营商网络。这样不仅提高了交换能力,更大范围降低对网络运营商的依赖性。
技术生态圈
有了世界顶尖的硬件环境,软件环境也不可少。下面我们着重介绍下Yahoo!的技术生态圈,看看Yahoo!使用了哪些产品和技术来支持大规模网络应用。
在雅虎内部构建一个超大规模应用其实并不是那么的复杂,因为我们已经提供了一整套完整的技术体系来帮助开发人员快速建立起一个具有高可维护性的超大规模应用。
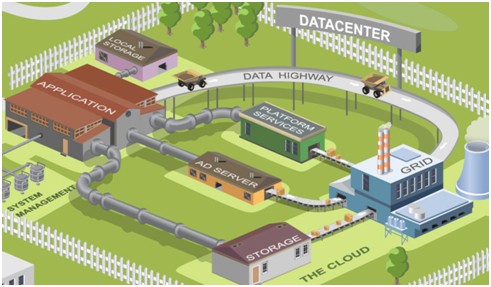
图3 Yahoo!数据中心技术生态圈
从这张图我们可以看到一个新应用在生态圈里和现有技术平台的关系:
新应用(APPLICATION)只需要更多的关注自身的业务逻辑。与应用密切关联的本地信息,我们有一些本地存储(LOCAL STORAGE)技术来供应用使用,比如关系性数据库MySQL、Oracle,存储Key-value型数据的MDBM和Memcache。另外,雅虎还提供了大量的平台服务(PLATFORM SERVICES)供我们各种应用使用。比如统一验证平台YCA来完成所有应用内及应用间的身份验证,统一防御平台Ydod来帮助我们识别并且隔离恶意/滥用的流量,用户信息服务UPS可以让应用方便的获取这个用户的相关信息,如地理位置,兴趣喜好等。个性化内容推荐服务Slingstone,可以直接向用户提供个性化的雅虎内部及合作伙伴的内容信息。另外新应用还能方便快捷的接入广告平台(AD SERVER),获取个性化推荐的广告。前端应用收集到的各种应用相关信息(如浏览点击数据),通过我们构建在全球骨干网络之上的数据高速公路(DATA HIGHWAY)这一统一数据通道,及时地回传到雅虎全球最大的商用Hadoop群集。在Hadoop群集上不同应用及平台服务根据各自的需求,处理对应的数据,并将处理好的数据在通过雅虎全球骨干网络分发到各个数据中心的服务端,以方便前端应用的调用。同时Yahoo!在云端(THE CLOUD)还提供共享的云存储(STORAGE),以方便全球化应用的同步和调用各种共享数据。
除了这些常见的技术来帮助快速构建超大规模应用,我们还提供了大量的技术和产品来进行高效的运维和管理:
- 主机信息管理系统:通过主机信息管理系统管理所有系统硬件信息,如CPU、内存、硬盘、网卡地址、Console接口、电源接口、物理位置等。
- 角色配置管理系统:主要是把主机根据角色分成不同的组,不同角色的主机会应用不同的配置。不同角色的主机有不同的运维团队、系统配置、应用配置等。
- 网络设备管理系统:包括交换机上的访问控制列表、负载均衡设备的配置、全球负载均衡配置,以及访问状态数据的统计。
- 统一的监控平台:用于从不同层面进行监控,我们有所有主机系统数据的监控,也有基于服务可用性的监控。然后我们也有访问量、访问延时等应用层面的数据监控,并可以和历史数据进行比较。
所有的这些平台大多都是雅虎运维团队自行开发和维护的,更贴合Yahoo!的使用体验,帮助对超大规模的主机进行统一和高效的管理。
运维团队
前面的两条分别是硬件和软件环境,除了一流的硬件和完备的软件环境,能够实现高可用性大规模应用的核心,还是人。所以我们在最后,会给大家介绍雅虎的全球运维团队是如何工作的。
在Yahoo!我们的运维团队除了基础设施的Operation团队,如数据中心现场工程师(SiteOps)、网络运维工程师(NetOps)、基础设施(DNS、DHCP等)运维团队(InfraOps)和安全团队(Paranoid)等。我们还会按照产品线划分出Service Engineer团队,来支持这项产品的应用运维。
SE(Service Engineer)团队和大部分公司的系统运维工程师一样,会负责生产系统维护,如部署应用、监控报警、配置管理、变更管理及故障管理。除此之外,在雅虎SE团队会更多的深入了解应用。

图4 团队协作
从产品设计之初,我们就会和产品经历及研发团队共同讨论系统架构设计,确保开发团队将要实现的是高可用性、高可扩展性及高可维护性的产品。产品测试阶段,我们也会和测试团队保持密切的沟通,使测试环境能够最大程度模拟生产环境的各种场景,以保证我们产品经过了完整有效的测试。系统上线前,我们还会和各个团队评估整个产品的可维护性,并确定应用的容量规划及其故障转移策略,确保SE团队充分了解如何在生产环境中维护该项产品。由于不同的团队可能在不同的国家和地区,所以只有更紧密的全球化协作,才能为用户提供一个高可用性、高可维护性的全球化产品。
产品上线以后,才是产品整个生命周期的开始,我们需要确保产品在其设计的生命周期内,都能够按照我们的预期提供高可用性的服务。所以在日常维护中,我们会和产品及研发团队一同分析产品运行状态,分析总结各种故障,不断的修正已有的Bug,提供新功能的建议与意见。根据各地用户分布及产品的运行状态,修正我们的容量规划及故障转移策略,进一步提升用户体验。
结语
以上只是雅虎在超大规模应用运维体系的简单概述,并没有太多的技术细节,瑾作抛砖引玉之用。雅虎全球运维团队的工程师利用他们的智慧,不断创新,一一应对各种挑战,完成一个个不可能完成的任务。