从Java到Clojure,大量使用NoSQL和云,MixRadio只为高效
【编者按】在“著名的推特论战:Microservices vs. Monolithic”一文中,我们曾分享过Netflix、ThougtWorks及Etsy工程师在Microservices上的辩论。在看完整个辩论过程后,或许会有一大部分人认同面向服务这个架构体系。然而事实上,Microservices的执行却并不简单。那么究竟如何才能打造一个高效的面向服务架构?这里我们不妨看向MixRadio首席架构师Steve Robbins的分享。
以下为译文
MixRadio提供了一个免费的音乐流服务,通过学习用户的收听习惯以交付一个定制化的电台,而用户需要做的只是去点击一些简单的按钮。通过极其简易的交互,MixRadio通过“移动优先”的方式提供了一个难以置信的定制化等级。它适用于任何人去发现新的音乐,不只是狂热的音乐发烧友。使用MixRadio就像打开一台收音机,但一切都在你的掌握之中――轻点Play Me,你的私人广播电台随之开启。基于地域流派和风格,MixRadio包括了数以百计的手工歌单、创建歌单功能,当然不能缺少保存喜爱的歌单并离线播放,这样即使没有互联网,美妙的音乐仍然可以继续。
当下服务已经在Windows Phone、Windows 8、Nokia Asha以及Web上可用,而支撑这些应用的后端系统则经过了数年的打磨,下面我们一起看看系统的架构概括。
架构综述
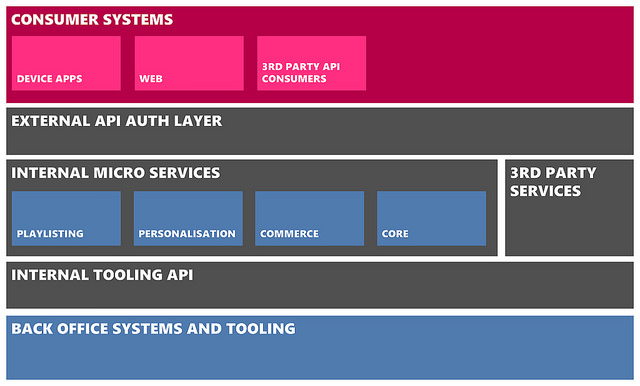
在2009年,我们如愿获得了重构后端系统的机会。而衍变到现在,后端系统已经由一系列RESTful服务组成,也就是大家经常说的“Microservices”。这些系统的功能、大小、开发语言、数据存储都各不相同,然而有一些共性是必不可少的,比如一些良好定义的RESTful API、独立扩展、监视能力。围绕这些核心服务,系统还拥有两个相似的代理服务,通过配置以提供RESTful资源的子集,它们被用于不同功能。“Internal Tooling API”代理服务器拥有内部API以提供客户服务、内容管理、歌单发布、监视以及其他场景使用的工具,客户端应用及第三方开发者使用的 RESTful API通过“External API auth layer”开放,这个服务同样负责执行适当的许可权限以及授权方案,比如OAuth2。
对于终端用户,通过API服务的应用程序范围非常广。我们提供了独立的HTML5网站、以及适用于Nokia电话和搭载Windows 8系统的设备应用,同时我们还开放部分相同的API给第三方开发者。下面我们不会公布过多的系统架构细节,如果想有更多详细了解可以查看我同事Nathan之前发布的文章。我们将对系统主要部分进行高度综述,下图显示了系统中由50多个Microservices构成的组件:
使用的技术
基于开源,我们务实地选择合适的工具以完成任务,下面一起看系统中重度使用的技术堆栈:
语言
- Microservices使用Clojure开发
- 设备应用和Media Delivery服务使用C#开发
- Web端则使用了HTML5、CSS和JavaScript
存储
- MySQL
- Solr
- MongoDB
- Redis
- Elasticsearch
- ZooKeeper
- SQLServer
基础设施
- Linux Microservices使用了AWS
- 媒体存储和运行在Windows上的媒体服务使用Azure
- GitHub Enterprise用于源码控制
- Packer用于建立机器镜像
- Puppet用于服务开通和主机镜像检查
监视
- Nagios
- Graphite
- Tasseo
- Seyren
- Campfire
- PagerDuty
- Keynote
- Logstash
- Kibana
架构原则
为了保持50多个Microservices API的一致性,我们在URL、结构、分页、排序、包装、语言代码等处理上都制定了标准;但是在一个开放的文化下,我们通常使用原则而非硬性规定来保持一致性。我们的服务需要遵循以下的条款:
- 松耦合、无状态,并且在HTTP上提供JSON RESTful接口。
- 独立部署并拥有自己的数据,也就是其他服务通过API访问数据,而不是数据库连接。这在持久性技术及数据结构改变时,服务仍然可以独立扩展。
- 不能太大,因为臃肿;不能太小,因为会浪费资源;我们为每个服务都使用了独立的主机实例。
- 实现健康检查API,用于监视和确定健康状态。
- 永远都不要破坏消费链。我们在早期就遵循在资源路径中添加版本号的标准(比如/1.x/products/12345/),这样一来,如果必须做破坏性改变,新的版本可以同时部署,并为上流消费者使用。尽管当下我们仍然保留了这个能力,但是已经数年未用。
遵循这些内部原则,对于外部公开API,我们有一些附加标准:
- API遵循移动优化:我们使用JOSN,因为在低性能设备上,对比XML,它只需要耗费很少的内存去解析;只要有可能,响应回应使用 GZIP编码,最重要的是,如果不需要,就不会返回数据。最后一点是对API一致性一个很好的平衡。
- 尽可能的使用缓存:API返回适当的缓存标头,这样一来,内容就可以在终端用户设备或浏览器上缓存,同时,我们还使用内容分发网络(CDN)来让内容离消费者尽可能的近。
- 尽可能多的在云中托管逻辑与数据,从而最大化减少应用中的逻辑副本并交付一个一致性体验。
- 第三方子集、Web、移动以及桌面客户端使用相同的API。然而,为了适应不同需求和屏幕大小,我们使用了大量的技术。举个例子,我们经常使用“itemsperpage”查询参数来调整返回内容数量;另一个关于RESTful API设计就是资源返回隔离的内容。内容经常被聚合到我们称为“views”的容器中,这样可以减少请求的数量。
使用视图API的一个例子就是应用中艺术家详情分页,数据从多个源中抽取――艺术家个人简介、图片、推特、gigs(混合了风格、热门歌曲、朋友听过的歌曲、相似的艺术家)。通过将这些集合到“view”中,应用每次都可以获得5千字节左右的数据。
让Microservices更快
近年内,我们一直进行Microservices从Java到Clojure的重写。Cloujure是个静态语言,仍然运行在Java Virtual Machine(JVM)之上,允许访问Java框架。后端团队之所以会选择Cloujure,大部分原因是速度――不管是开发还是运行时。Cloujure比Java来的更为简洁,举个例子,有一个使用Java编写的Microservices在使用Cloujure重编写后,代码量从44000减少到4000行(包括所有配置、测试及组件)。我们使用Leiningen来加速开发,Leiningen提供的一个特性就是自定义项目模板来加速开发,我们拥有一个被称为“cljskel”的模板作为所有服务的框架模板。在后续文章中我们将详细介绍这个模板,而在使用方面,我们可以运行下面的命令,并获得一个功能RESTful服务,它将具备监视API:
lein new cljskel <project name>
如果你感兴趣我们为什么会深入Clojure,你可能会对2013年两个工程师在London的演讲感兴趣。
数据
我们有两个最大的数据源,分别是3200万+音轨的内容元数据(包括相关的艺术家、专辑、混合等)和来自应用程序的分析数据(比如回放、顶/踩以及浏览事件)。
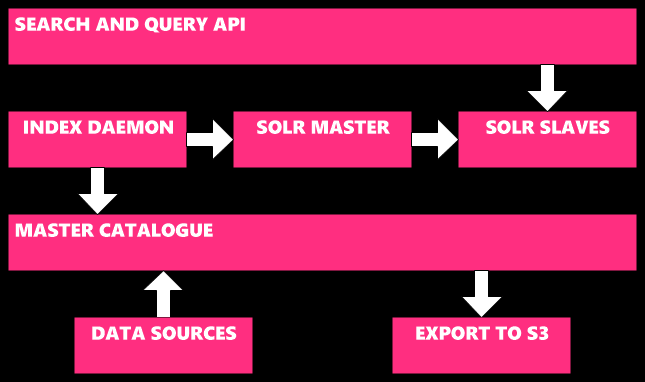
Catalogue服务为消费者体验提供了内容元数据和搜索能力,Master Catalogue则存储来自多个数据源中的元数据,比如唱片公司、公司内部内容团队、以及类似维基百科这样的互联网资源。一个配置驱动的数据模型指定如何合并资源(比如基于内容团队在其他源中的更改对指定字段进行更新),这里的字段都可以被搜索并返回调用者。针对不同的用例,我们可以返回不同的字段。比如,有时候在搜索结果中我们并不需要一个节目列表清单,但是在显示曲目列表详情时我们则需要这个字段。Master Catalogue服务不会直接支撑用户流量,取而代之,“Search and Query”API则是其余后端系统的接口。Search and Query服务基于Apache Solr建立,Index Daemon则会抓取Master Catalogue用以修改并推送给Solr搜索索引。
在定制化体验、进行A/B测试、CRM、计算业务指标过程中,收集常用和分析数据至关重要。随着连续不断的数据从各种应用中传到后端,许多服务都需要对相同的数据同时访问。举个例子,当某个用户踩某首歌曲时,这对当下播放的曲目列表有着重要的意义,有助于对一个用户品位的把握,再三的重复踩这个动作意味着这个艺术家可能并不为用户喜欢。为了能处理预期的数据,我们确定了预期中订阅/发布系统所具备的特性:
- 高可用,不能有任何单点故障
- 通过去耦为整个系统提供高扩展性,并且具备暂停摄入消息的能力
- 允许对消息格式不可知
- 低写入延时
- 为订阅者快速提供输出
- 提供简单的订阅/发布API
- 支持同数据多订阅,同时每个都可能有不同的架构,以不同的速度和调度处理。比如实时处理和批聚合(或者存档)。
我们选择了LinkedIn出品的Apache Kafka,因为它近乎完美地迎合了我们的需求。作为一个稳定的消息系统,它被设计用于支撑不同状态(比如读取数据的位置)的用户,而不是所有用户都是一尘不变的存在,并且以同样速度消费数据。
监视
系统的目标是主要用例延时不超过0.8秒,以及在90天周期内4个9的可用性,相当于每个月停机4.3分钟。因此当错误发生时,我们要快速的发现并处理问题。在这里,我们使用了多个监视层来提醒开发和运维工程师。
最底层,我们使用Nagios来检查虚拟机的健康状况,并通过PagerDuty来提醒运维工程师。系统中,每个Microservices都会实现健康检查API,让AWS负载均衡器来确定某个主机是否需要被重启(在之前的报告中,你可以了解更多关于AWS负载均衡器的配置信息)。Graphite被使用以收集操作系统级度量,比如CPU使用率、磁盘空间等。同时,每个Microservices都会根据工程师需求记录对应度量。服务度量会在不同等级上进行,比如低等级的HTTP 500错误计数,以及高等级的抽象(被激活订阅数量),我们测量一切需要的信息。下面是Graphite可视化界面的一个截图:
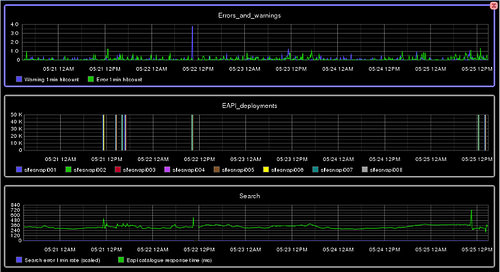
在Graphite之上我们使用了Tasseo,它会提供一个更友好的数据总结视图;同时,在阈值变化时,我们使用Seyren进行提醒。Tasseo最早是由几个工程师引进,它曾被用于2012年奥巴马再次竞选时的系统。

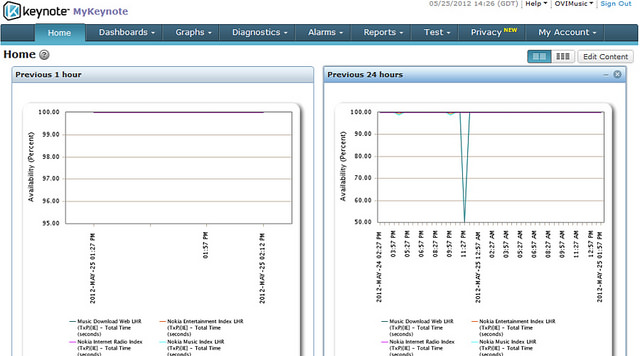
在最高等级中,我们通过Keynote测量用例和全世界范围内的响应时间:
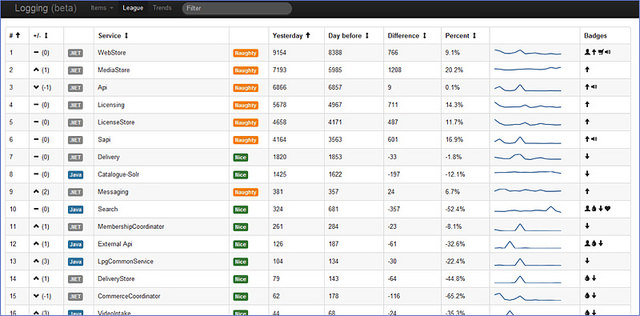
最终,为了做更详细的监测,我们避免必须通过日志传输来连接到特定服务器的情况。通过Logstash集中收集系统、请求、错误和应用程序特有日志,并且使用Kibana配合定制仪表盘来追踪特殊错误或者趋势。下面这个例子是我们几年前定制的仪表盘,目的是减少应用程序错误噪声:
持续交付
持续交付是自动部署和测试的一个实践,主要关注软件是否可以被快速并以重复的途径发布。多年来,我们一直致力这方面的提升,当下已经过渡到Netflix基于AWS的“red / black”模式。在今年6月份的London Continuous Delivery Meetup上,我们工程师Joe分享了这方面的内容。
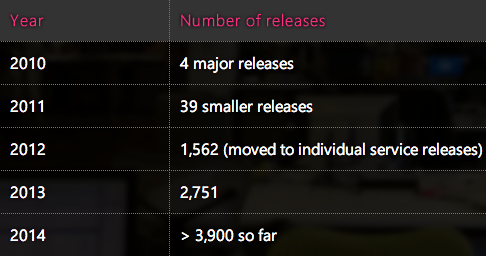
你可以通过观察我们在过去5年发布的软件数量来查看架构提升:
原文链接: MixRadio Architecture - Playing With An Eclectic Mix Of Services (翻译/童阳 责编/仲浩)