从桌面到移动:异构计算翻天覆地的技术变革
在今天智能手机领域中有这样一个趋势,美国Qualcomm公司提倡使用DSP去处理手势操作、陀螺仪等传感器所需的计算任务。这可以帮助CPU分担部分计算任务,又节省了电能的消耗。现在很多SoC厂商也开始意识到了这一点,例如苹果会考虑在iPhone 5S中加一颗Cortex-M7处理器,来处理传感器、计步器等对性能要求较低,而对功耗要求较高的场景下的计算。那么从桌面计算架构,到今天的移动设备的计算架构,异构计算是如何演化,又是如何影响我们的技术革新的?本文将为您详细解析。
异构计算:把各种果料压成一块切糕
典型的异构计算应用,也并不是一个新话题。早在20世纪80年代中期,异构计算技术就诞生了。它主要是指使用不同类型指令集、体系架构的计算单元组成混合系统的一种特殊计算方式。异构计算(Heterogeneous computing)主要是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式。常见的计算单元类别包括:CPU(中央处理器)、GPU(图形处理器)、CO-Processor(协处理器)、DSP(信号处理器)、ASIC(专用集成电路)、FPGA(现场可编程门阵列)等。
异构计算近年来得到更多关注,主要是因为通过提升CPU时钟频率和内核数量而提高计算能力的传统方式遇到了散热和能耗瓶颈。而与此同时,GPU等专用计算单元虽然工作频率较低,具有更多的内核数和并行计算能力,总体性能、芯片面积比和性能、功耗比都很高,但芯片的性能却远远没有得到充分利用。
从广义上讲,不同计算平台的各个层次上都存在异构现象。除硬件层的指令集、互联方式、内存层次之外,软件层中应用二进制接口、API、语言特性底层实现等的不同,对于上层应用和服务而言,都是异构的。
从实现的角度来说,异构计算就是制定出一系列的软件与硬件的标准,让不同类型的计算设备能够共享计算的过程和结果。同时不断优化和加速计算的过程,使其具备更高的计算效能。本文所讲述的异构,是指的CPU与其他计算元器件之间的异构计算演进,从硬件与软件的角度,讲述他们的发展历程。

并行计算:让处理的速度变得更快
相对于串行计算,并行计算可以划分成时间并行和空间并行。时间并行即流水线技术,空间并行使用多个处理器执行并发计算,当前研究的主要是空间的并行问题。以程序和算法设计人员的角度看,并行计算又可分为数据并行和任务并行。数据并行把大的任务化解成若干个相同的子任务,处理起来比任务并行简单。
空间上的并行导致两类并行机的产生,按照麦克・弗莱因(Michael Flynn)的说法分为单指令流多数据流(SIMD)和多指令流多数据流(MIMD),而常用的串行机也称为单指令流单数据流(SISD)。MIMD类的机器又可分为常见的五类:并行向量处理机(PVP)、对称多处理机(SMP)、大规模并行处理机(MPP)、工作站机群(COW)、分布式共享存储处理机(DSM)。
从自然哲学层面上来讲:任何最为复杂的事情,都可以被拆分成若干个小问题去解决。这构成了现代并行计算的哲学理论依据。然而在当今的双路、四路、八路甚至多路处理器系统中,并行计算的概念早已得到广泛应用。曾经业界最为普及的并行计算规范就是OpenMP。
OpenMP:同构计算最为普及的标准
OpenMP(Open Multi-Processing)是由OpenMP Architecture Review Board牵头提出的,并已被广泛接受的,用于共享内存并行系统的多线程程序设计的一套指导性注释(Compiler Directive)。OpenMP支持的编程语言包括C语言、C++和Fortran;而支持OpenMP的编译器包括Sun Studio和Intel Compiler,以及开放源码的GCC和Open64编译器。OpenMP提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些pragma,或者编译器不支持OpenMP时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。

OpenMP的特色
OpenMP提供的这种对于并行描述的高层抽象降低了并行编程的难度和复杂度,这样程序员可以把更多的精力投入到并行算法本身,而非其具体实现细节。对基于数据分集的多线程程序设计,OpenMP是一个很好的选择。同时,使用OpenMP也提供了更强的灵活性,可以较容易的适应不同的并行系统配置。线程粒度和负载平衡等是传统多线程程序设计中的难题,但在OpenMP中,OpenMP类库从程序员手中接管了部分这两方面的工作,可以自动均衡负载。
OpenMP的缺点
作为高层抽象,OpenMP并不适合需要复杂的线程间同步和互斥的场合。OpenMP的另一个缺点是不能在非共享内存系统(如计算机集群)上使用。由此如果我们想将不同类型的计算器、计算机联和起来,协同工作。由此,我们就需要使用更为复杂的异构计算技术。

蒙昧期:从32bit到64bit
2003年以前,对于台式机来说还是32bit的时代。处理器制造厂商,不断提升制造工艺技术,使用更精细的制程来制造处理器。同时也不断提高处理器的时脉,如133MHz、166MHz、200MHz、300MHz……最终频率提升到了3GHz后,就难作寸进了。到目前为止我们也未曾见到Intel和AMD发布高于4GHz主频的处理器产品。
2003年出现了x86-64,有时简称为“x64”。这是64位微处理器架构及其相应指令集的一种,也是Intel x86架构的延伸产品。“x86-64”最初是1999年由AMD设计,AMD首次公开64位集以扩充给IA-32,称为x86-64(后来改名为AMD64)。其后也为Intel所采用,Intel称之为“Intel 64”,在之前还曾使用过Clackamas Technology (CT)、IA-32e及EM64T等称呼。外界多使用"x86-64"或"x64"去称呼此64位架构,从而保持中立,不偏袒任何厂商。
AMD64代表AMD放弃了跟随Intel标准的一贯作风,选择了像把16位的Intel 8086扩充成32位的80386般,去把x86架构扩充成64位版本,且兼容原有标准。
AMD64架构在IA-32上新增了64位暂存器,并兼容早期的16位和32位软件,可使现有以x86为对象的编译器容易转为AMD64版本。除此之外,NX bit也是引人注目的特色之一。
不少人认为,像DEC Alpha般的64位RISC芯片,最终会取代现有过时及多变的x86架构。但事实上,为x86系统而设的应用软件数量实在太庞大,x86的整个生态系统基石深厚。这也成为Alpha不能取代x86的主要原因,AMD64的成功在于,能有效地把x86架构移至64位的环境,并且能兼容原有的x86应用程序。
CPU中出现多处理核心
2006年出现了双核心多核心。多核心,也叫多微处理器核心是将两个或更多的独立处理器封装在一起的方案,通常在一个集成电路(IC)中。双核心设备只有两个独立的微处理器。一般说来,多核心微处理器允许一个计算设备在不需要将多核心包括在独立物理封装时执行某些形式的线程级并发处理(Thread-Level Parallelism,TLP)这种形式的TLP通常被认为是芯片级多处理。如3D游戏这样的密集型运算场景中,您必须要使用驱动程序来调用第二颗处理核心的计算资源。
此后处理器制造厂商发现,利用多核心架构可以在不提升处理器频率的情况下,继续不断提升处理器的效能。这也让摩尔定律有机会一路走下去。
GPGPU:开启通用计算大门
随着CPU性能发展放缓,人们开始寻求新的性能爆点。2008年出现了通用计算单元这一概念。通用图形处理器(General-purpose computing on graphics processing units,简称GPGPU),是一种利用处理图形任务的图形处理器来计算原本由中央处理器处理的通用计算任务。这些通用计算常常与图形处理没有任何关系。由于现代图形处理器强大的并行处理能力和可编程流水线,令流处理器可以处理非图形数据。特别在面对单指令流多数据流(SIMD),且数据处理的运算量远大于数据调度和传输的需要时,通用图形处理器在性能上大大超越了传统的中央处理器应用程序。
3D显示卡的性能从NVIDIA的GeForce256时代就颇受瞩目,时间到了2008年,显示卡的计算能力开始被用在实际的计算当中。并且其处理的速度也远远超越了传统的x86处理器。
CPU+GPU:异构计算悄然兴起
对于GPGPU表现出的惊人计算能力叫人为之折服,但是在显卡进行计算的同时,处理器处于闲置状态。由此处理器厂商也想参与到计算中来,他们希望CPU和GPU能够协同运算,完成那些对计算量有着苛刻要求的应用。同时也希望将计算机的处理能力再推上一个新的高峰。这里更多的是希望GPU能参与到CPU计算任务中来,让GPU分摊大部分机械性的大规模计算任务。一时间,世界上的超级计算机都开始了大提速。

天河当自强,异构显神威
说个老黄历,国际TOP500组织TOP500.org在网站上每半年会公布最新的全球超级计算机TOP500强排行榜。2010年11月14日,国际TOP500组织在网站上公布了最新全球超级计算机前500强排行榜,中国首台千万亿次超级计算机系统“天河一号”排名全球第一。实测运算速度可以达到2.566 petaFLOPS(每秒万亿次)。
该计算机共耗资6亿元人民币,由103台机柜组成,占地面积约1000平方米,装有3072颗Intel的至强E5540 2.53GHz四核处理器和3072颗至强E5450 3.0GHz四核处理器,共有24,576个处理器核心。天河一号还装备2560块AMD Radeon HD 4870 X2显示卡,共有5,120个图形处理器用于图形处理器通用编程。天河一号拥有98TB内存和1PB共用的磁盘容量。全系统功率为1280千瓦。

迥异:不同计算架构的特点
上面提到的采用的异构计算架构都属于大型计算机的范畴。对于个人计算机而言,尤其是x86架构的计算机,异构计算的步伐则要慢许多。这是因为,无论是处理器还是显示卡,又或者其他运算部件,都有其自身的架构和特性。他们是针对不同领域,面向不同应用所设计的芯片。所以他们在功能性方面千差万别。要想将他们都统一起来,除了需要制定共同的规范和标准之外,还要针对其计算的特点设计软件。
举例来说,CPU和GPU在进行计算时,就有许多不同。对于处理器来说,它是一颗通用处理器。它要应对各种类型的计算应用。无论是数学方面的,还是逻辑方面的运算。我们可以看到,一颗比较常规的处理器其中的ALU计算单元仅仅占据整个核心面积的25%以内。在处理器中,超过50%的核心面积用来制作Cache高速缓存,无论是L1、L2还是片上的L3。而另外还有25%的核心面积用来作为控制器。它控制着处理管线的运作,控制着各种分支预测,让多核心处理器可以更有效率。
而我们再反观GPU,其结构要简单的多。GPU的任务是加速3D像素的计算。因此我们在显卡中可以看到数以百计的流处理器单元或者是CUDA核心。而在整个计算过程中,GPU承担的逻辑计算任务非常小。同时它有着更宽的显存带宽,有着更高速的显存。所以在GPU芯片中,也就无需更大容量的片上缓存机制。
通过上文的分析,我们可以看到CPU的在处理时,适合作所有工作,各个方面都比较平均。逻辑处理能力要比GPU快,但是对于数学计算方面,其速度不如具有海量处理核心的GPU快。而GPU方面,数学计算性能强大,大规模并行处理机制强大,但是逻辑处理能力不足,仅仅能在某些计算领域应用。
FireStream:慢慢淡出我们的视野
Firestream是AMD旗下的品牌系列之一。与Radeon(用于消费级显卡)和FirePro(用于专业显卡)不同,FireStream主要用于AMD的高性能计算卡系列。FireStream产品中的GPU不是用来作3D加速用途,而是利用GPU内置的流处理器变成一群并行处理器,作为浮点运算协处理器,协助中央处理器计算复杂的浮点运算程序,例如复杂的科学运算。Firestream的竞争对手是nVIDIA的Tesla系列高性能计算卡。
早在数年前,人们就意识到GPU不但可以处理图形数据,还可以处理其他数据。BionicFX就试过利用GeForce 6800处理音频数据,ATI亦做过同样的试验。而且史丹佛大学的Folding@Home研究项目亦可利用Radeon X1900作运算加速;通过GPU来模拟蛋白质合成,进而找寻有关蛋白质的疾病。
第一个产品,FireStream 580,是建基于R580图形芯片。它将是一块采用R580显核的特殊显示卡,R580显示核心中的48个独立的像素处理器能带来强大的浮点运算性能。该产品采用PCI Express x16作为接口,流处理器的频率是600 MHz,可以同时运行512线程,并配备了1GB GDDR3存储器,频率是1300 MHz。并有可能使用多个核心并发处理数据。这个流处理器的功耗为165W。

CUDA:在夹缝中挣扎求存
CUDA(Compute Unified Device Architecture,统一计算架构)是由NVIDIA所推出的一种集成技术,是该公司对于GPGPU的正式名称。通过这个技术,用户可利用NVIDIA的GeForce 8以后的GPU和较新的Quadro GPU进行计算。亦是首次可以利用GPU作为C-编译器的开发环境。
目前为止基于 CUDA 的 GPU 销量已达数以百万计,软件开发商、科学家以及研究人员正在各个领域中运用 CUDA,其中包括图像与视频处理、计算生物学和化学、流体力学模拟、CT 图像再现、地震分析以及光线追踪等等。
它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。开发人员现在可以使用C语言来为CUDA架构编写程序,C语言是应用最广泛的一种高级编程语言。所编写出的程序于是就可以在支持CUDA的处理器上以超高性能运行。
CUDA v3.0以后,开始支持C++和FORTRAN。实际上,CUDA架构可以兼容OpenCL或者自家的C-编译器。无论是CUDA C-语言或是OpenCL,指令最终都会被驱动程序转换成PTX代码,交由显示核心计算。目前CUDA v6.5 RC已经可用,包含了对ARM 64bit架构的支持等一些先进的特性。

PhysX:最出色的GPGPU应用实例
PPU(Physics Processing Unit)物理处理单元是一种特别为减轻CPU 计算,尤其是物理运算部分的处理器,您可以把它看做是一颗协处理器。这概念类似于对上10年间GPU。在现代计算机中,GPU用于处理矢量图形,并且延伸到3D图形。但GPU对物理处理无能为力,故目前大部分物理处理都交给CPU处理,这无疑是加重了CPU本来就不轻的负担。
NVIDIA PhysX是一套由AGEIA 设计的执行复杂的物理运算的PPU,又可以代表一款物理引擎。AGEIA 声称,PhysX 将会使设计师在开发游戏的过程中,使用复杂的物理效果,而不需要像以往那样,耗费漫长的时间开发一套物理引擎。以往使用了物理引擎,还会使一些配置较低的电脑,无法流畅运行游戏。AGEIA 更宣称 PhysX 执行物理运算的效率,比当前的 CPU 与物理处理软件的组合高出 100 倍。游戏设计语言Dark Basic Pro将会支持PhysX,并允许其用户利用 PhysX 执行物理运算。在 2005年7月20日,索尼同意在即将发售的PlayStation 3中使用AGEIA 的PhysX和它的SDK――NovodeX 。现时,AGEIA公司己被NVIDIA收购,相关的显卡亦可以加速该物理引擎。
PhysX设计用途是利用具备数百个内核的强大处理器来进行硬件加速。加上GPU超强的并行处理能力,PhysX将使物理加速处理能力呈指数倍增长并将您的游戏体验提升至一个全新的水平,在游戏中呈现丰富多彩、身临其境的物理学游戏环境。
APU:台式机上的异构计算芯片
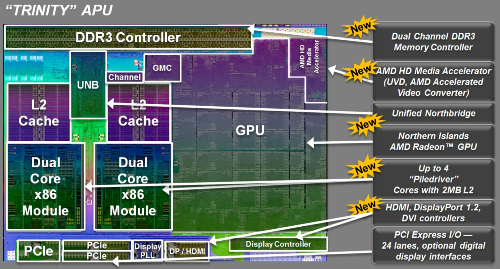
AMD在并购ATI以后,随即公布了代号为“AMD Fusion”(融聚计划)。简要地说,这个项目的目标是在一块芯片上,集成传统中央处理器和图形处理器,并且内置最少16通道、可与外部PCI-E设备链接的PCI-E控制器,存储器控制器等。而这种设计会将北桥芯片从主板上卸载,集成到中央处理器中,CPU核心还可以将原来依赖CPU核心处理的任务(如浮点运算)交给为运算进行过优化的GPU处理(如处理浮点数运算)。AMD认为这是加速处理单元(APU)的一类,是为AMD加速处理器(AMD Accelerated Processing Units,AMD APU)。
2011年的CES上,AMD展示了Llano处理器,这是一颗真正意义上的异构计算处理器。从这张这新架构图中,我们可以看到Llano具备四个处理核心,每一颗核心具有不同类型的L1高速缓存。同时每一个处理核心具备512KB X 2的容量为1MB的L2高速缓存。由此在处理器的部分,构成了4MB的二级缓存。
在整个芯片接近50%的面积上,是GPU的部分。一颗处理芯片同时包含了CPU和GPU的部分,这可以说是非常典型的异构计算架构。同时,在芯片的两边我们也可以看到高度集成的4个PCIe总线控制器,还有一个128bit位宽的DDR3内存控制器。
这样的异构计算芯片可以充分发挥不同计算部件的优势。当需要进行较多逻辑计算时,可以使用CPU部分完成。当需要大量的浮点运算时,可以借用GPU的浮点运算处理管线来完成。同时如果处理器的某些核心正处于空闲,也可以让其加入到计算中来。由此可见异构计算不仅仅是需要统一起不同类型的计算部件,同时也需要有针对性的让更适合的硬件作适用的计算工作。
OpenCL:异构计算真正开始闪耀
2008年6月的WWDC大会上,苹果提出了OpenCL规范,旨在提供一个通用的开放API,在此基础上开发GPU通用计算软件。随后,Khronos Group宣布成立GPU通用计算开放行业标准工作组,以苹果的提案为基础创立OpenCL行业规范。
OpenCL (Open Computing Language,开放计算语言) 是一个为异构平台编写程序的框架,此异构平台可由CPU,GPU或其他类型的处理器组成。OpenCL由一门用于编写kernels(在OpenCL设备上运行的函数)的语言(基于C99)和一组用于定义并控制平台的API组成。OpenCL提供了基于任务分区和数据分区的并行计算机制。
OpenCL类似于另外两个开放的工业标准OpenGL和OpenAL,这两个标准分别用于三维图形和计算机音频方面。OpenCL扩展了GPU用于图形生成之外的能力。OpenCL由非盈利性技术组织Khronos Group掌管。
OpenCL最初苹果公司开发,拥有其商标权,并在与AMD,IBM,英特尔和nVIDIA技术团队的合作之下初步完善。随后,苹果将这一草案提交至Khronos Group。2010年6月14日,OpenCL 1.1 发布。

早在2008年,苹果制定OpenCL大家都以为是桌面端的布局,苹果希望通过OpenGL来让自家的Mac电脑可以顺利的使用两个显卡巨头的产品做GPGPU运算。苹果的这一举措却为未来的x86平台异构计算奠定了坚实的基础。因为无论是CUDA还是FireStream,无论是CUDA核心还是流处理器,软件开发人员都可以通过OpenCL来支持。
但是在2014年的今天看来,苹果的这步OpenCL秒棋,也深深的影响到了移动产业。先卖个关子,且听下文说到移动端再细细分解。
DirectCompute:立足DX11,应用广泛
Microsoft DirectCompute是一个应用程序接口(API),允许Windows Vista或Windows 7平台上运行的GPU进行通用计算,DirectCompute是Microsoft DirectX的一部分。虽然DirectCompute最初在DirectX 11 API中得以实现,但支持DX10的GPU可以利用此API的一个子集进行通用计算,支持DX11的GPU则可以使用完整的DirectCompute功能。
C++ AMP:微软的异构计算编程语言
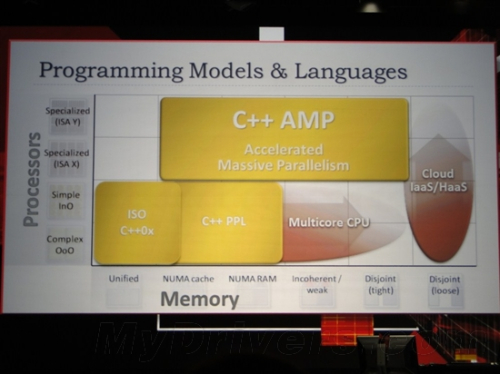
相比OpenGL丰富的功能和体系化的SDK来说,DirectCompute仅仅是以一个简单的API存于世上,显然不能赢得更多厂商的关注。OpenCL作为一种开放的并行加速计算标准,已经得到了AMD、Intel、NVIDIA等芯片业巨头和大量行业厂商的支持,但唯独缺少了微软。就在AMD Fusion开发者峰会上,微软终于拿出了自己的反击武器:“C++ AMP”,其中AMP三个字母是“accelerated massive parallelism”的缩写,也就是加速大规模并行的意思。
C++ AMP是微软Visual Studio和C++编程语言的新扩展包,用于辅助开发人员充分适应现在和未来的高度并行和异构计算环境。通过使用 C++ AMP,您可以为多维数据算法编码,以便通过使用异类硬件上的并行对执行进行加速。 C++ AMP编程模型包括多维数组、索引,内存传输、平铺和数学函数库。 您可以使用C++ AMP语言扩展控制数据在CPU和GPU之间相互移动的方式,从而提高性能。C++ AMP现已加入Visual Studio 2013豪华午餐。不过它也有门槛,仍然需要DX11以上的硬件支持,才能运行。
为了与OpenCL相抗衡,微软宣布C++ AMP标准将是一种开放的规范,允许其它编译器集成和支持。这无疑是对OpenCL的最直接挑战。最近几年,微软一直在推C++ AMP,但是作为开放标准的OpenCL,也注定了其生态会更加的繁荣。
移动GPU:用来一键“美白”
以往多数人对GPU的印象是其功能仅应用于游戏。但事实上,GPU所能完成的工作不仅仅是运行大型的3D游戏,我们可以利用它的计算特性做很多重要的事情。比如Qualcomm Snapdragon系列的SoC芯片中,包含了三块具备较大处理能力的单元:Krait CPU、Adreno GPU和Hexagon DSP。如何更好的利用这三个计算单元,成为了移动应用开发者们必备的新“常识”。
CPU的整数运算能力很强,GPU的浮点计算能力更强。而DSP的特性和GPU还是有一些差别。DSP更倾向于处理有时间序列的任务。比如多媒体编解码任务,这是DSP最擅长做的。在视频编解码过程中的通常算法,是会根据前后两帧之间的差值来进行计算。因此DSP更适合去做一些机械的、简单的计算工作。它最大的特点就是功耗低,使用它做计算可以更省电。

GPU近年来的应用场景一直在不断的拓展。这是因为很多新兴的应用类型,都对浮点运算有着很高的要求。举例来说,用户可能会在拍照之后,用图片处理应用对照片进行“美白”、 “磨皮”、增加曝光度、增加色彩饱和度等一系列复杂的处理。这些都可以用到GPU强大的并行计算特性。
庞大的数据处理,一直是手机拍照的技术难题。未来手机上的图片处理软件,将不得不考虑使用更为高效的方式来处理如此大容量的图片。现在前置摄像头的规格,少则200万像素,多则500、800万像素。后置的摄像头,未来主流1300万像素起,甚至有些手机都用上了4千万像素的CMOS。
摄像头像素规格――系统需要实时处理的数据量
- 8 megapixel COMS――12 MBytes
- 13 megapixel COMS――19.5 MBytes
- 21 megapixel COMS――31.5 MBytes
- 41 megapixel COMS――61.5 MBytes
在图片处理应用中,直接调用GPU的计算能力,会比调用某些所谓的8核心CPU更好、更快、更省电。又例如,很多具备所见所得滤镜的视频录制应用,用户在手机屏幕上可以实时的看到“老照片”、“黑白”、“反色”、“美肤”等视频滤镜的效果。这种情况下就需要调用GPU来对实时滤镜进行渲染处理。
RenderScript:Google的移动异构方案
直到最近Google开始推RenderScript之后,异构计算的这股热潮才逐渐袭来。RenderScript是Android平台的一种类C的脚本语言(使用C99语法),开发难度比OpenCL要小一些。之前Google在各个Android版本的动态壁纸中用该技术实现3D图形特效,直到Android 3.0才集成到SDK中来。
RenderScript的移植性还是不错的。传统的NDK编写代码时,必须事先在开发机上为每一个目标原生平台来编译。而RenderScript可以在目标设备上编译,生成更高效的二进制代码。这也就意味着只要硬件支持RenderScript,不管采用什么架构,都可以运行您的的RenderScript代码。
但不幸的是,Google对OpenCL兴趣不大,因为那是苹果主导的异构联盟。Google在Android 4.3系统之后,从Android上彻底铲掉了对OpenCL的支持。
使用RenderScript,程序员不用关心设备底层细节,不用考虑在不同Android设备的移植问题。不用考虑特定的CPU、GPU还是DSP,完全有驱动自行优化。对于想做深度优化的程序员来说,RenderScript就是一个看不见的黑盒子。另一边的OpenCL则展现出了更多硬件细节,对于高级程序员来说,是一个可以充分榨干硬件性能,充分发挥异构计算特性的强大法宝。按照Google官方的说法,他们摒弃OpenCL的原因是不想在各种设备上再看到分裂和不兼容的情况,他们想统一硬件和软件标准,才做出的这个“艰难的决定”。
Qualcomm:建议开发者用SDK优化APP
幸运的是,Qualcomm也正积极参与Khronos Group制定OpenCL标准的工作。同时它还是异构系统架构基金会(HSA Foundation)的创始会员。Qualcomm从Adreno 330 GPU起,已经可以支持OpenCL、RenderScript和OpenGL ES 3.0(甚至还有DX11和曲面细分)。这会为移动应用开发者带来极大的方便。
Qualcomm在GPU运算、DSP运算和异构计算方面给开发者提供了完备的SDK,包括Adreno SDK(GPU方面)、Hexagon SDK(DSP方面)、FastCV(视觉计算)MARE SDK(并行计算)等方面。对于应用开发者而言,最重要的就是要使用Qualcomm的SDK来优化自己的应用,无需再被底层的复杂工作困扰。Snapdragon SoC系统内部会自动识别任务的复杂程度,并调用相应的计算单元来完成执行。

asynchronous SMP:多核异步处理器
先说一下,标准的ARM架构,都是Simultaneous Multi-Processing(SMP多核同步处理器)架构。然而asynchronous SMP(aSMP多核异步处理器)是Qualcomm自己提出来的,目前在Snapdragon中的Krait CPU,都是采用的这种多核异步的工作方式。
之前很多不明真相的“砖家”都说这是胶水处理器,只是把处理核心黏在一起。事实上,异步和同步的差异仅仅是在处理核心的工作频率上。这称作异步时脉架构(Asynchronous Clock Architecture,ACA)异步处理中,每个处理核心的工作电压和频率都是不同的。一切设计都是为了移动设备要尽可能的节电为大原则。可以让一个时钟频率较高的处理核心,去运行繁重的计算任务。让低频工作的处理核心运行不是那么紧急,计算量相对较小的任务。而多核同步处理器则没有这个优势,所有处理核心都会工作在相同的电压和频率下。
当然,在Krait CPU中的共享L2高速缓存,也可以根据处理任务量的不同,工作在不同的电压和频率下。从而最大限度的节省电能。

Qualcomm MARE SDK:移动设备并行运算利器
Qualcomm发布的的MARE(多核异步运行环境)是一种用于并行及异构移动计算的编程模型和运行时系统。这种原生C++库提供了一种简单而优雅的方式在多个CPU核心上实现并行计算,并且可以利用MARE SDK在GPU上实现异构计算。
MARE SDK作为用户级库实施,与Android NDK相集成,提供易于使用的并行编程原语言。其应用级摘要帮助开发者利用任意Andriod设备上的多进程硬件进行并行计算,而不需要深入了解有关该硬件的知识。
目前,最新版的MARE SDK已经支持并行编程模式,这是一个包括并行迭代、并行图、并行前缀扫描和同步数据流在内的集合。这些模式通过优化执行通用并行习语,可进一步简化编程。另外也为诸如矩阵乘法等线性代数例程增加了对Snapdragon处理器的特定支持。
采用MARE SDK之后,一般能为需要密集计算的应用,如拍照类应用的实时滤镜,带来性能的大幅优化,1个工程师,2天时间,图像处理速度提高60%。线程管理和并行计算只占用五分之一的Pthread代码。无论采用何种设备或处理器,只在Google Play中出现一个单一.apk文件。

big.LITTLE:助力达成8核心、64bit
当移动SoC跨越到64bit世代,移动设备不仅仅要省电,还要高性能。在一些高端机型上,我们会经常看到这样的架构配置:4 + 4核心,即4颗负责高强度运算任务的Cortex-A57核心,还有4颗在“闲暇”时负责计算任务的Cortex-A53。然而实现这样丰富的异构计算核心技术,就是ARM所提供的big.LITTLE。
运算能力强的处理器核心,与低耗电、运算能力弱的处理器核心,结合在一起。运用在移动计算上,多核心处理器能具备较高性能的同时,其平均功耗也能维持在较低的水平。
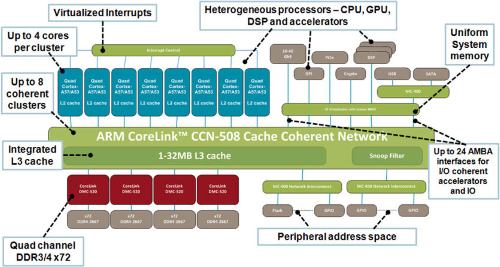
基于ARMv8体系架构的Cortex-A53和Cortex-A57处理器在采用big.LITTLE技术协作运行时,处理器将通过 CoreLink CCN-504 一致性互连来连接,以实现具有完全一致性的高性能众核解决方案。该解决方案支持在一块硅晶片上容纳多达16个内核。
经测量,对于中等强度的工作负载(例如 Web 浏览),节能达到 50%。而对于后台工作负载(例如 mp3 音频播放),节能高达 70%。
AMD在下一盘大旗:ARM + X86
2014年5月,在互联网上疯狂转发着一张PPT,一个全新的x86与ARM共融核心。AMD对此并未过多提及,只是在介绍自主设计K12 ARM架构的同时,有一个小小的注脚写着“开发64位ARM核心,以及新的64位x86核心”。
这两种新架构都会由AMD的首席架构设计师Jim Keller统领负责。他强调说:“AMD的特长是打造高频率核心,并且会将AMD大核心的高性能、ARM小核心的低功耗完美融合在一起。”
我们大致可以明白,AMD引入ARM的技术,是为处理器进一步降低功耗,以应对未来的移动计算大趋势。然而另我们好奇的是,这两种架构如何在一起协同工作?统一的架构接口和指令集是必要的。

总结:异构计算未来必将丰富多彩
异构计算的未来会相当丰富。在桌面端,将继续依靠GPU的大规模并行计算能力,不断突破人类计算的极限。而在手机端big.LITTLE将联合不同类型的CPU,展现出强大的性能。
未来的移动计算,需要闲时更加省电,这需要借助DSP、低功耗处理器的帮忙。同时也需要在瞬时展现出更强大的性能,而这更需要借助移动GPU进行异构计算。
作为移动应用的开发者,可以借助RenderScript开发出强大的Android应用。更可以使用如Adreno SDK、MARE SDK等第一方芯片厂商的方案,轻松为应用做更深层的优化。