程序员游戏Style:亚特兰大极客使用机器学习玩转Flappy Bird
【编者按】Flappy Bird虽然下架了,但是相信仍有一大部分人还挣扎在它的阴影之下――游戏看似简单,但得分只在小两位数上徘徊,有时甚至是可怜的一位数。搜狗产品经理@光芊源更简单的分析了这个游戏会火的原因:用户往往抱着“可以拿高分”的心态,却总是因为“没注意”而失败。在回答中,网友@任杰还进行了适当的补充:1,Restart成本很低,秒秒钟的事情;2,平滑的难度曲线,再开始不会感到突兀。不管出于什么原因,Flappy Bird确实火了一把――不仅稳坐App Store和Google Play免费应用排行榜将近一个月,下载量高达5000万次,好评59万条,应用内平均每天广告收入更达5万美元。然而,这个火爆绝对是建立在无数玩家的“痛苦”之上,于是在几番高分无果的情况下,来自CAMPUS BUZZ的小伙SarvagyaVaish决定从自己的专业入手,使用机器学习玩转这头笨拙的小鸟。
以下为译文:
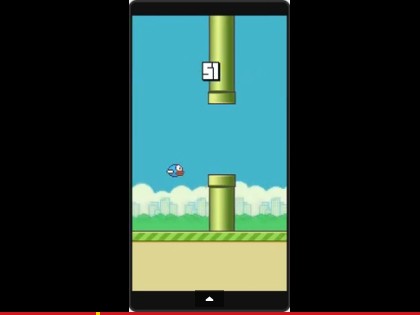
观看视频请访问原文
这是流行游戏Flappy Bird上的一次极客运动,尽管这个游戏已经在App Store和Google Play下架,但是网络上还流行着许多山寨应用,比如Flappy Bird Typing Tutor和Flappy Math Saga。在玩了几分钟这个游戏后,我看到了一个检验自己机器学习技巧的实践机会――让小鸟学会如何自己来玩游戏,而上面这个视频也证明了经过良好训练的Flappy Bird基本上已经可以完全躲避障碍。
机器学习过程
开始时我的选择是Android应用,计划使用Monekyrunner来获取画面和点击命令,然而Monekyrunner 1到2秒的画面捕捉时间完全满足不了我的最低需求。随后,我发现了@mrspeaker的游戏引擎、Omega500以及用于typing的Flappy Bird版本,这些都非常适合我们的用例,于是我就果断拆掉了它的typing组件并添加了一些Q Learning代码。
强化学习
这里有一些基本规则:智能体,也就是这里的Flappy Bird,在某个状态下总会执行一个特定的动作,而在状态发生改变后会得到相应的奖励。基于情况的不同,有许多不同的变体会被使用,比如:Policy Iteration、Value Iteration、Q Learning。
关于Q Learning的详细介绍可以点击这里,下面则是算法:

状态矢量空间
在这里一共设计了3个参数:1,小鸟与低管道的垂直距离;2,小鸟与下一个管道出口的水平距离;3,小鸟是否死亡。

行为
对每个状态,我设计了两个可能存在的行为:点击或者是什么都不做。
奖励
奖励完全依赖于“Life”参数,仍然存活则+1,失败则-1000。
学习循环
数组Q初始化为0,同时也总采取最佳操作,这些操作将最大化我的预期奖励。
第一步,观察Flappy Bird所处的状态,并执行可以最大化预期奖励的操作。让游戏引擎执行“tick”操作,随之Flappy Bird进入下一个状态s’。
第二步,观察s’及状态下的奖励,+1则表示小鸟还活着。
第三步,通过Q Learning规则来修改Q数组。Alpha的值被设置成0.7,因为我们需要一个确定的状态,也让学习的可能最大化;同时,Y和lambda都被设置成了1。
第四步,将当前状态设置为s’并重新开始。
结语
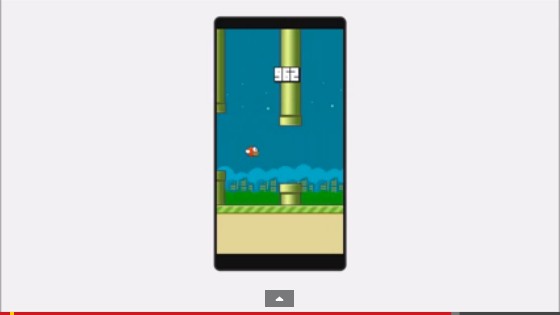
完整视频请访问原文
初步训练成功大约花了6-7个小时(得分150+),学习速度通过使用更多的例子来提升,最后将它们的经验贡献给同一个数组。另一个提升学习途径的方式是输入更好的学习数据。更多代码详情可见FlappyBirdRL GitHub页面。
原文链接:
Flappy Bird hack using Reinforcement Learning(编译/仲浩 审校/毛梦琪)